介绍
目前,单幅图像的超分辨率重建大多都是基于样本学习的,如稀疏编码就是典型的方法之一。这种方法一般先对图像进行特征提取,然后编码成一个低分辨率字典,稀疏系数传到高分辨率字典中重建高分辨率部分,然后将这些部分汇聚作为输出。以往的SR方法都关注学习和优化字典或者建立模型,很少去优化或者考虑统一的优化框架。
为了解决上述问题,本文中提出了一种深度卷积神经网络(SRCNN),即一种LR到HR的端对端映射,具有如下性质:
①结构简单,与其他现有方法相比具有优越的正确性,对比结果如下:
②滤波器和层的数量适中,即使在CPU上运行速度也比较快,因为它是一个前馈网络,而且在使用时不用管优化问题;
③实验证明,该网络的复原质量可以在大的数据集或者大的模型中进一步提高。
本文的主要贡献:
(1)我们提出了一个卷积神经网络用于图像超分辨率重建,这个网络直接学习LR到HR图像之间端对端映射,几乎没有优化后的前后期处理。
(2)将深度学习的SR方法与基于传统的稀疏编码相结合,为网络结构的设计提供指导。
(3)深度学习在超分辨率问题上能取得较好的质量和速度。
图1展示了本文中的方法与其他方法的对比结果: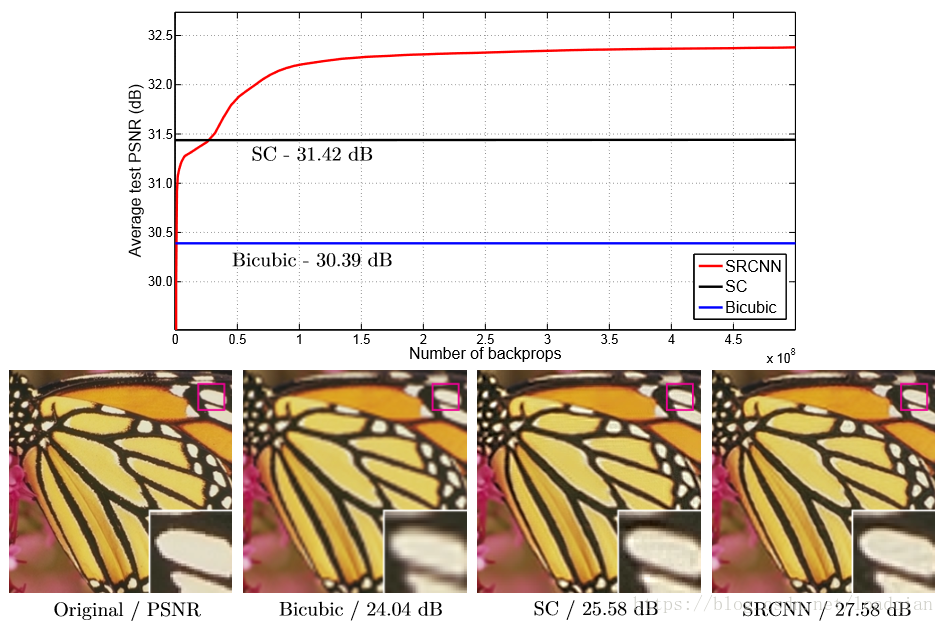
基于卷积神经网络的超分辨率
公式化
使用双三次插值将单幅低分辨率图像变成我们想要的大小,假设这个内插值的图像为Y,我们的目标是从Y中恢复图像F(Y)使之尽可能与高分辨率图像X相似,为了便于区分,我们仍然把Y称为低分辨率图像,尽管它与X大小相同,我们希望学习到这个映射函数F,需要以下三部:
(1)特征提取:从低分辨率图像Y中提取patches,每个patch作为一个高维向量,这些向量组成一个特征映射,其大小等于这些向量的维度。
公式: 第一层定义为函数F1:
F1(Y) = max(0,W1 ∗Y + B1)
其中,W1和B1分别代表滤波器和偏差,W1的大小为c*f1*f1*n1, c 是输入图像的通道数,f1是滤波器的空间大小,n1是滤波器的数量。从直观上看,W1使用n1个卷积,每个卷积核大小为c*f1*f1。输出是n1给特征映射。B1是一个n1维的向量,每个元素都与一个滤波器有关,在滤波器响应中使用Rectified Linear Unit (ReLU,max(0,x))
(2)非线性映射: 这个操作将一个高维向量映射到另一个高维向量,每一个映射向量表示一个高分辨率patch,这些向量组成另一个特征映射。
公式: 第二步将n1维的向量映射到n2维,这相当于使用n2个1*1的滤波器,第二层的操作如下:
F2(Y) = max(0,W2 ∗F1(Y) + B2).
其中,W2的大小为n1*1*1n2,B2是n2维的向量,每个输出的n2维向量都表示一个高分辨率块(patch)用于后续的重建。
当然,也可以添加更多的卷积层(11的)来添加非线性特征,但会增加模型的复杂度,也需要更多的训练数据和时间,在本文中,我们采用单一的卷积层,因为它已经能取得较好的效果。
(3)重建: 这个操作汇聚所有的高分辨率patch构成最够的高分辨率图像,我们期望这个图像能与X相似。
公式: 在传统的方法中,预测的重叠高分辨率块经常取平均后得到最后的图像,这个平均化可以看作是预先定义好的用于一系列特征映射的滤波器(每个位置都是高分辨率块的“扁平”矢量形式),因此,我们定义一个卷积层产生最后的超分辨率图像:
F(Y) = W3 ∗F2(Y) + B3
W3的大小为n2*f3*f3*c,B3是一个c维向量。
如果这个高分辨率块都在图像域,我们把这个滤波器当成均值滤波器;如果这些高分辨率块在其他域,则W3首先将系数投影到图像域然后再做均值,无论哪种情况,W3都是一个线性滤波器。
将这三个操作整合在一起就构成了卷积神经网络,在这个模型中,所有的滤波器权重和偏差均被优化,网络结构如图2: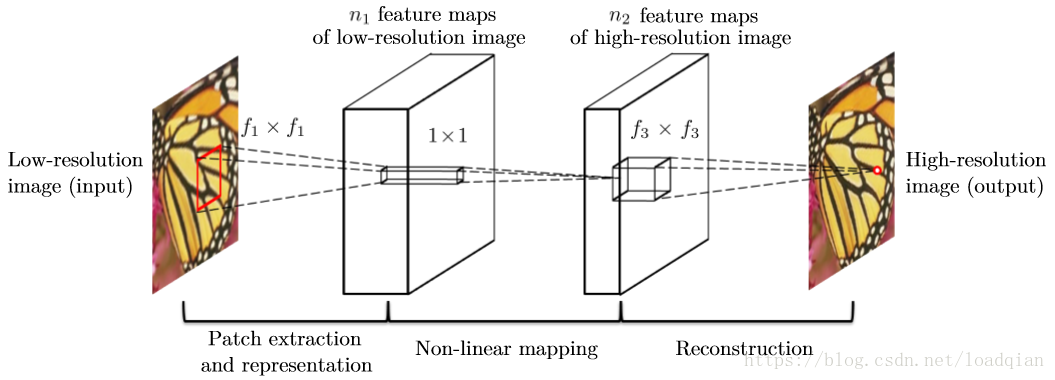
与基于稀疏编码方法的关系
基于稀疏编码的图像超分辨率方法也可以看作是一个卷积神经网络,如图3: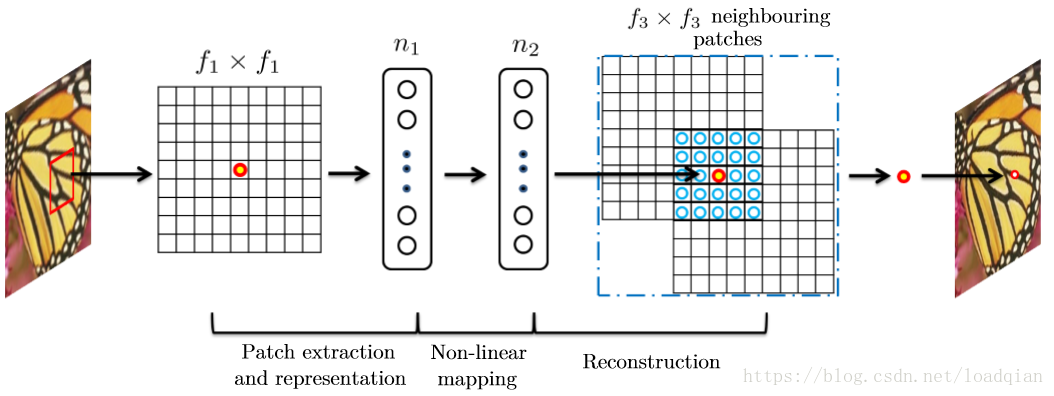
在稀疏编码方法中,假设f1f1大小的低分辨率块是从输入图像中提取的,这一小块减去它的均值,然后投影成一个低分辨率的字典,如果这个字典大小为n1,就等价于对输入图像使用n1个线性滤波器(f1\f1)(减去均值也是一个线性操作,所以可以被吸收),这部分在上图左半部分中可以看到。
接下来,稀疏编码器将n1个系数投影输出n2个系数,通常n1=n2,这n2个系数代表高分辨率块,从这个角度看,稀疏编码器表现得像一个非线性映射操作,这部分在上图中间呈现。然而,这个稀疏编码器不是前馈形式,它是一个迭代算法。相反,我们的非线性操作是前反馈的而且可以高效计算,可以认为是一个全连接层。
上述得n2个系数被投影到另一个高分辨率字典,产生一个高分辨率块,所有重叠的块取平均。这等价于对n2个特征映射的线性卷积。假设这些用于重建的高分辨率小块大小为f3*f3,则线性滤波器也有相同的大小f3*f3,看上图中的右半部分。
上述讨论展示了基于稀疏编码的SR方法可以看成是一种卷积神经网络(非线性映射不同),但在稀疏编码中,被不是所有的操作都有优化,而卷积神经网络中,低分辨率字典、高分辨率字典、非线性映射,以及减去均值和求平均值等经过滤波器进行优化,所以我们的方法是一种端对端的映射。
上述分析帮助我们决定超参数,我们设置最后一层滤波器尺寸小于第一层,这样可以更多地依赖于高分辨率块的中心部分,如果f3=1,那么中心的像素不能进行平均。一般设置n2<n1,这样可以更稀疏。典型的参数设置为f1=9, f3=5, n1=64, n2=32(在实验部分评估了更多的参数设置)
损失函数
学习端对端的映射函数F需要评估以下参数: Θ = {W1,W2,W3,B1,B2,B3}。最小化重建函数F(Y;Θ) 与对于的高分辨率图像X之间的损失,给出一组高分辨率图像 {Xi} 和对应得低分辨率图像 {Yi},使用 均方误差(Mean Squared Error,MSE)作为损失函数: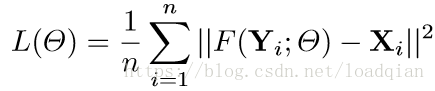
其中,n为训练样本数,损失的最小化使用随即梯度下降法和标准的BP算法进行反向传播。
使用MSE作为损失函数有利于得到较高的PSNR值,PSNR是图像复原方法中一个常用的评价指标。
实验
数据集:为了与传统方法公平的比较,我们使用相同的训练集和测试集,训练集包含91张图像,Set5用来衡量放大因子为2,3,4的结果,Set14用来评价放大因子为3的情况,除了这91张图像,我们后续使用了更大的训练集。
对比: 将我们的SRCNN与以往的方法SC (sparse coding) 、K-SVD、NE+LLE (neighbour embedding + locally linear embedding) 、ANR (Anchored Neighbourhood Regression) 进行对比。
实现细节: 设置f1 = 9, f3 = 5, n1 = 64 and n2 = 32 。对于每个方法因子 ∈{2,3,4}训练一个特定的网络。
在训练过程中,真实图像{Xi}为随机从训练图像中剪裁的32*32大小的子图。为了合成低分辨率样本{Yi},我们将子图用一个适当的高斯核进行模糊,子样本通过放大因子得到,用双三次插值以相同的因子进行放大,91张图像大约可以得到24800张子图,子图从原图像中提取,stride为14。
为了在训练中避免边界的影响,所有的卷积层都没有padding。每一层的滤波器权值初始化满足均值为0,标准差为0.001的高斯分布,偏差为0,前两层学习率为10-4,最后一层为10-5,我们发现最后一层使用更小的学习率比较容易收敛
定量评价
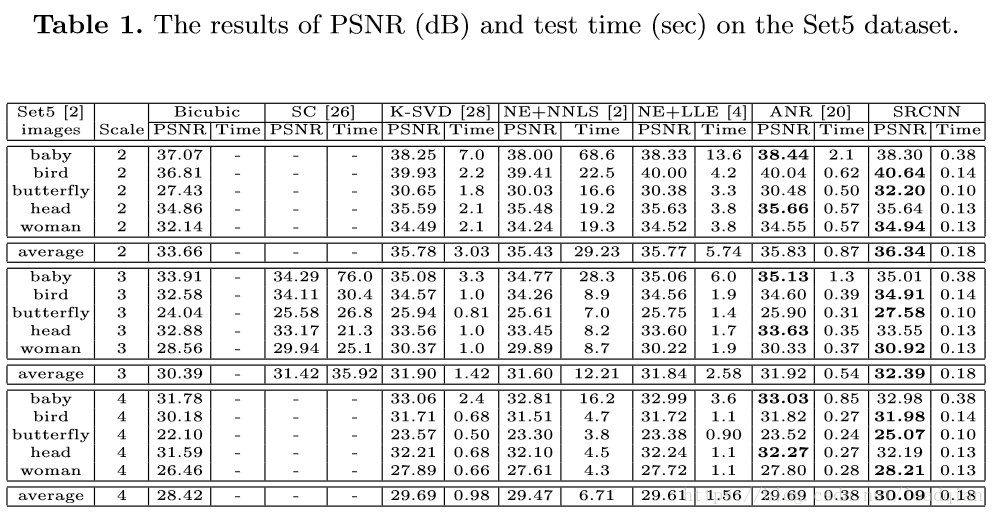
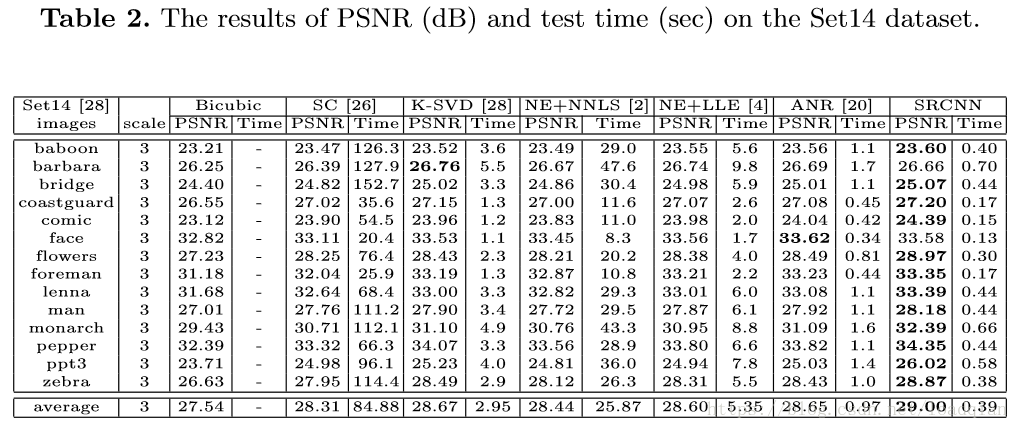
从表1,2中可以看到,本文提出的SRCNN在所有的实验中PSNR的平均值最大,且表1中平均PSNR比第二好的ANR分别高出0.51dB,0.47dB,0.40dB.由于Set5的数据集有限,所以结果不是决定性的。来看拥有更大数据集的Set14的结果,SRCNN的平均PSNR与其他方法相比有较大优势(>0.3dB)
进一步分析
从ImageNet中学习超分辨率:
我们从ILSVRC2013ImageNet选择295909张图像,使用步幅 stride=33分解得到5百万张子图,仍然使用上述参数,由于BP反向传播次数相同(8*10e8),所以与91张图的训练时间差不多,在Set5上放大3倍进行测试,其收敛曲线与其他方法的比较如下: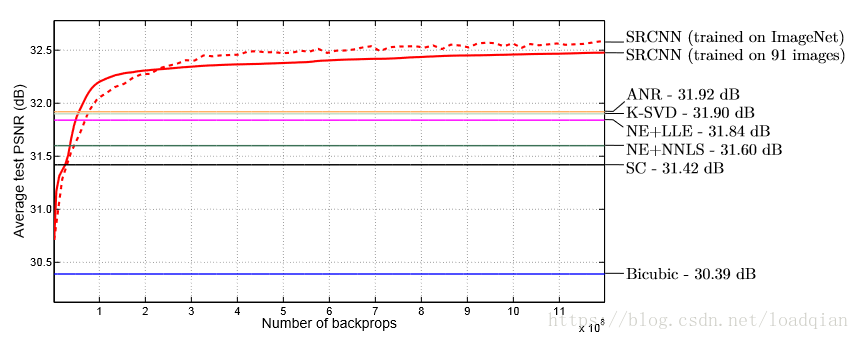
可以看到,使用相同的BP数量,SRCNN+ImageNet可以达到32.52dB,高于原始的在91张图像的结果 32.39 dB ,结果表明,使用更大、更多样化的图像训练集可以进一步提高SRCNN的性能。
滤波器数量:
之前的实验中我们使用的时n1=64,n2=32,接下来我们分别对n1=128,n2=64和n1=32,n2=16分别在ImageNet中训练,在Set5的方法因子为3时进行测试,结果如下:
可以看出,随着滤波器数量的增加,实验的结果会越好。但如果你期望一个较快的复原速度,就可以使用小规模的网络结构,实验效果也比之前的方法好。
滤波器大小
在之前的实验中,f1 = 9 ,f3 = 5;接下来将 f1 = 11 ,f3 = 7,其他参数均不变来进行实验,得到的PSNR为32.57dB,比之前的32.57dB稍微高了一点, 也就是说滤波器越大,就能获得越多的结构信息,也会得到更好的实验结果,但时间更长。因此,网络规模的选择往往是时间和性能的权衡。
结论
我们提出了一种新的深度学习方法用于单幅图像的超分辨率重建,传统的基于稀疏编码的方法可以看作一个深的卷积神经网络。本文提出的SRCNN方法是一种在LR和HR图像之间的端对端映射,在优化时几乎不需要额外的预处理和后处理,结构也比较简单,比以往的方法都要好。我们推测,通过在网络中探索更多的隐藏层/过滤器以及不同的训练策略,可以进一步提高性能。此外,该结构简单且鲁棒性强,能运用到低水平的视觉问题中,例如图像去模糊、同步SR+去噪。同时,该网络结构可以处理不同的放大因子。来看几个实验结果:
