介绍
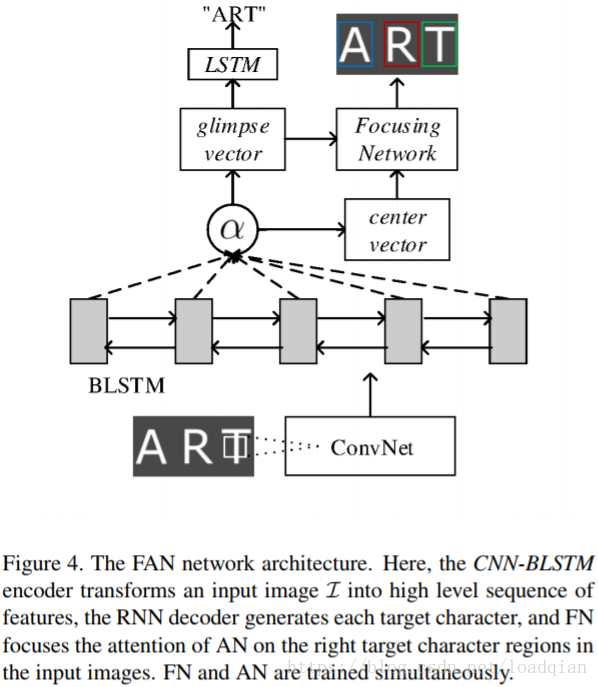
对于一些复杂的或者质量低的图像,现有的基于注意力(attention-based)的方法识别效果很差,我们研究发现其中一个主要的原因是使用这种注意力模型评估的排列很容易损坏由于这些复杂或质量低的图像。换句话说,注意力模型(attention model)不能精确地联系特征向量与输入图像中对应的目标区域,这种现象称为attention drift。为了解决这个问题,本文提出了一种新的方法,称为FAN(Focusing Attention Network)来精确地识别自然图像中的文本。FAN主要由两个子网络组成:AN(attention Network)和现有方法一样,用于识别目标字符;FN(Focusing Network)通过检查AN的注意区域是非在图像中目标字符的正确位置,然后自动地调整这个注意点,下图直观地展示了这两个网络的功能。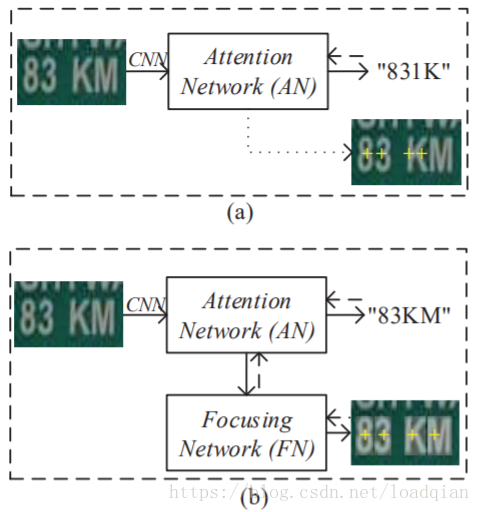
本文的主要贡献:
(1)提出了attention drift的概念,解释了使用现有的基于注意力的方法处理复杂、低质量的自然图像会得到很差效果的原因;
(2)提出了一个新的模型FAN来解决上述问题,AN在很多现有方法已经存在,FN是新引入的,可以将注意点转移到目标区域上;
(3)我们采用了一个强大的基于ResNet的卷积神经网络(CNN)以丰富场景文本图像的深度表征;
(4)在不同的数据集上做了大量实验,我们的方法比现有的方法取得更好的效果。
FAN方法
FAN包含两部分:AN和FN,在AN部分,由目标标签和特征产生alignment factors,每个alignment factor对应输入图像中的注意力区域;FN部分先定位目标标签的注意力区域,对注意力区域进行密集的预测得到对应的glimpse vector他,通过这种方式,FN可以判断glimpse vector是否合理。总之,FN基于AN给出的glimpse vector,对输入图像的注意力区域产生密集的输出,AN根据FN的反馈来更新glimpse vectors。
AN
AN解码器使一个循环神经网络(RNN)直接从输入图像I产生目标序列(y1,…….yM)。在实验中,I通常用CNN-LSTM编码成一个特征向量序列,Encoder(I)=(h1, …, hT ),在第t步,解码器产生一个输出yt
yt = Generate(st, gt)
其中st是在t时刻RNN的一个隐藏状态,
st = RNN(yt−1, gt, st−1)
其中,gt是连续特征向量(h1,……hT)的权值和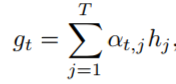
其中, 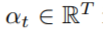 是注意力向量的权重,也叫做alignment factors,αt由(h1,……hT)中每个元素的得分来评估,用下式对得分进行归一化:
是注意力向量的权重,也叫做alignment factors,αt由(h1,……hT)中每个元素的得分来评估,用下式对得分进行归一化: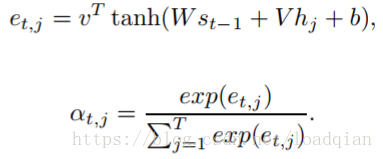
其中,v,W,V,b都是可训练的参数。
这里,Generate函数和RNN函数分别表示一个反馈网络和LSTM循环网络。此外,解码器需要产生一个可变长度的序列,在目标集中添加 special end-of-sentence (EOS),因此解码器可以在EOS发散时完成字符的生成,注意力模型的损失函数定义为: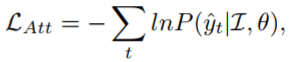
其中,yt^第t-th的真实字符,θ是一个结合了整个网络参数的向量。
AN模型有两个缺点:1)该模型很容易受到复杂或低质量的图像的影响,产生不精确的alignment factors,导致注意力区域与真实区域的偏差,这就是我们之前提到的attention drift现象;2)在数据很大时,这个模型很难训练。例如800-million的真实数据。在本文中,我们主要解决attention drift现象。
FN
为了解决attention drift现象,引入FN网络,focusing-mechanism如图: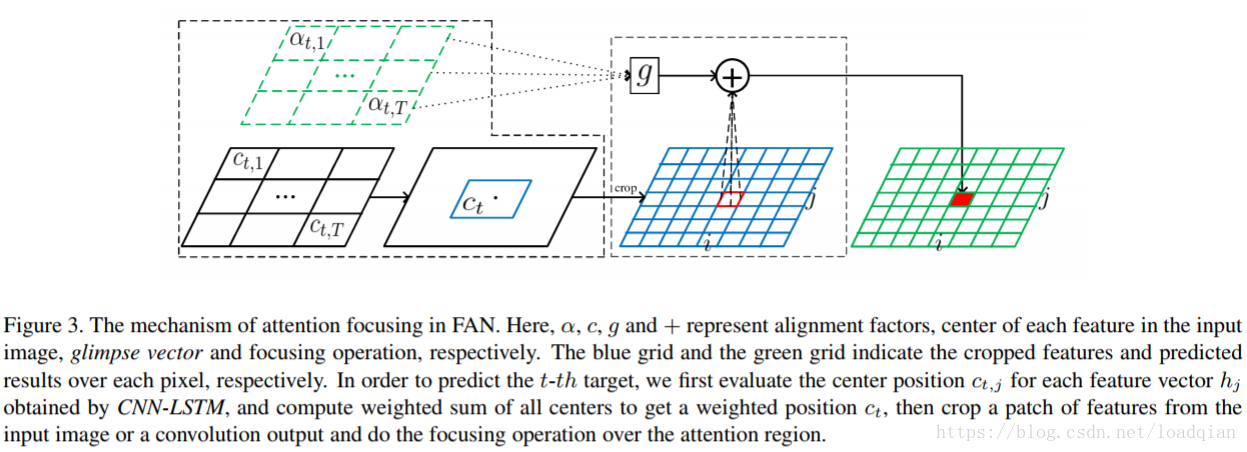
主要包含两步:1)计算每个预测标签的中心注意点;2)通过生成注意力区域的概率分布来将注意力集中在目标区域
计算中心注意点:在卷积或池化操作中,我们定义输入为N × Di × Hi × W,输出为N × Do × Ho × W,其中N, D, H,W分别表示batch size,通道数,特征映射的高度和宽度,根据卷积策略中的kernel,stride,pad,我们可以有:
Ho = (Hi + 2 × padH −kernelH)/strideH + 1
Wo= (Wi + 2 × padW − kernelW)/strideW + 1
在L层(x,y)位置处,我们计算L-1层的感受野为边界坐标r = (xmin, xmax, ymin, ymax),如下: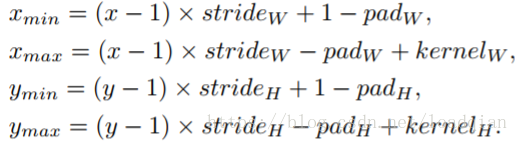
在第t步,输入图像的感受野hj循环使用上式计算得到,然后选择感受野的中心作为注意力的中心:
c t,j = location(j)
其中,j为hj的下标;location函数用于评估感受野的中心,因此,输入图像中的目标yt的注意力中心可以用下式计算: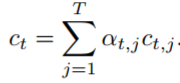
将注意力集中在目标区域:计算出目标yt的注意力中心后,我们可以从输入图像或者其中的一次卷积输出中得到一组特征映射 P(PH,PW ),如下: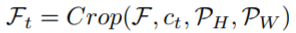
其中,F为图像或者卷积特征映射,P是输入图像中真实区域的最大值。
有了剪裁后的特征映射,我们可以计算注意力区域的能力分布: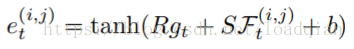
其中,R和S分别Wie可训练的参数,(i,j)代表第(i × PW + j)个特征向量。可能性概率可表示为: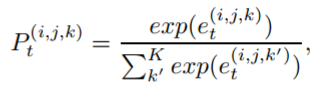
其中,K为标签类别的数量。
然后,我们定义focusing的损失函数: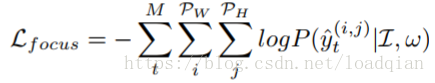
其中,ytˆ(i,j)是真实的像素标签,ω是结合整个FN中参数的向量。损失只对带有字符注解的图像子集会增加。
FAN Training
目标函数同时考虑target-generation 和attention-focusing,如下: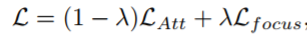
使用一个可调参数λ (0 6 λ < 1),用于衡量AN和FN的影响,这个网络使用标准的BP训练。
解码
基于注意力的解码器使为了产生输出字符序列,在无约束的字符识别中,我们直接选择可能性最大的字符;然而在有约束的识别中,依据不同大小的辞典,我们计算所有单词的条件概率分布,然后选择可能性最大的作为我们的输出结果。
实验评估
数据集
IIIT 5K-Words(IIIT5K)
Street View Text (SVT)
ICDAR 2003 (IC03)
ICDAR 2013 (IC13)
ICDAR 2015 (IC15)
具体设置
网络:32层ResNet-based CNN,如上表所示来获得更深层次的文本特征。
表1中残差网络块:{[kernel size, number of channels]×}、{stride, pad} = {0, 0}
其他卷积层:{kernelW ×kernelH, strideW × strideH, padW × padH, channels}
池化层: {kernelW × kerneH, strideW × strideH, padW ×padH}
H和W分别为特征映射的高和宽。从CNN中提取的特征序列进入BLSTM (256 hidden units)网络中。对于字符生成任务,注意力设置成一个LSTM (256 memory blocks)和37个输出单元 (26 letters, 10 digits, and 1 EOS symbol)。对于FAN,我们从输入图像中裁剪特征映射且设置λ = 0.01。
模型训练:使用ADADELTA优化方法,训练我们的模型在8百万的合成数据没有pixel-wise标记和4百万带标签的,大约30%有pixel标签。设置batch size=32,图像大小25632。每秒90个样本,epochs=3,约5天后收敛。
*运行环境::CAFFE框架、CUDA GPU加速
实验结果
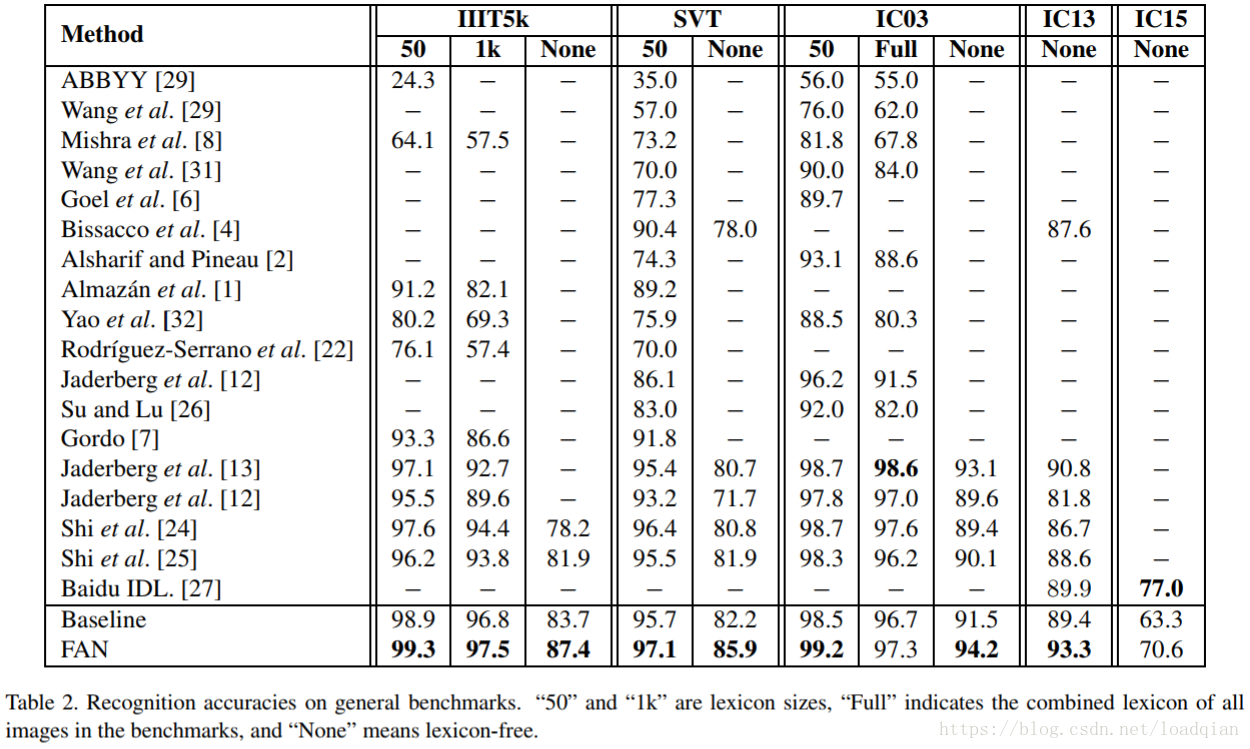

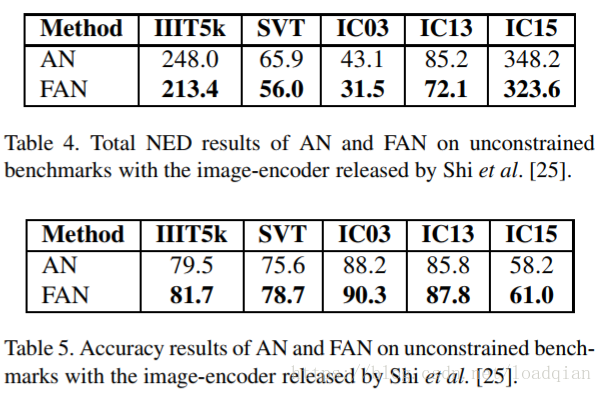
原文后续还有关于参数λ和Pixel Labeling的影响,可参考原文,这里不详述。
结论
在本文中我们给出了attention drift的概念解释了为什么现有的AN方法对复杂或低质量的图像识别效果很差,继而提出一种新的方法FAN来解决这个问题。不同于现有方法,FAN使用创新的focusing网络来改进AN模型处理复杂低质量图像的drifted attention ,大量的实验证明我们的方法比现有的方法效果好。
原文链接:
https://arxiv.org/pdf/1709.02054.pdf