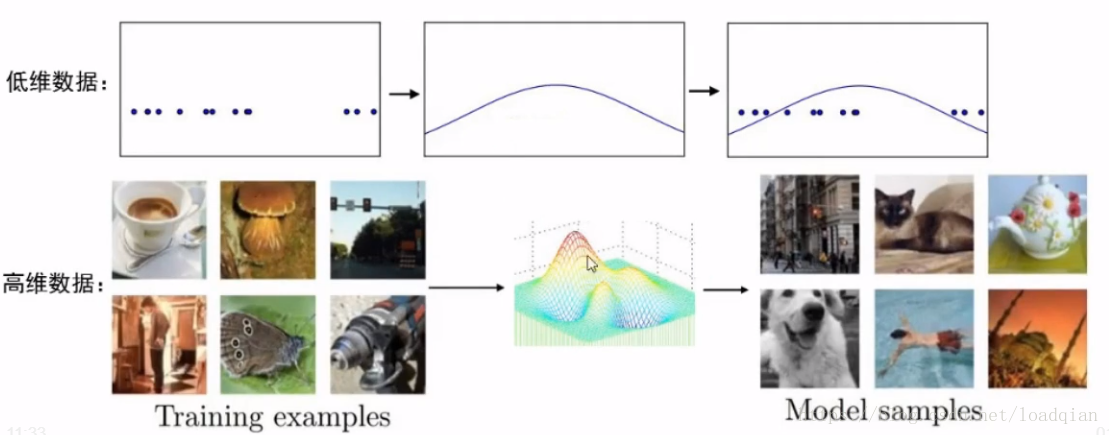
GAN究竟在做什么?
学习样本集的数据分布
A.学习数据分布有什么用?
(1) 学习到高维抽象的分布函数
(2) 模拟预测未来数据
(3) 处理缺省数据问题:如半监督学习
(4) 生产真实样本
建立模型,分析数据特征,还原数据,……
B.如何生成真实样本?
C.生成模型的一些常见方法:
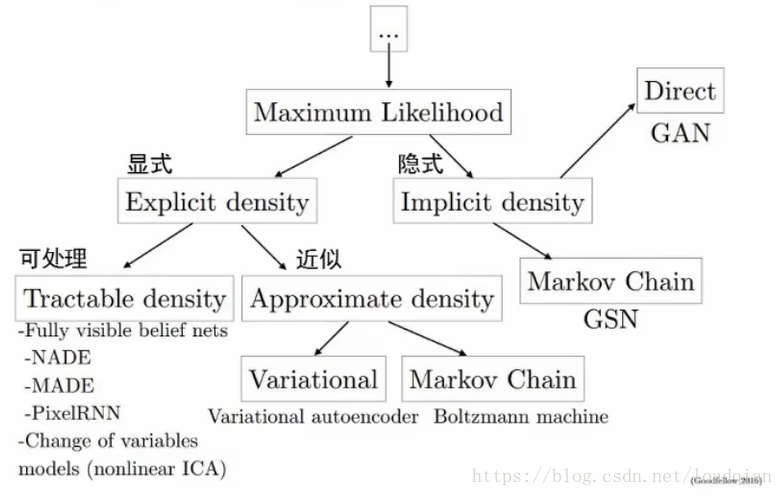
D.生成模型常见方法的比较:
显式:或多或少的需要知道或者假设模型的分布;大多通过Markov chains方法
隐式:使用隐藏编码,无需假设模型,无需Markov chains,以最终生成图像的相似性作为目标
GAN如何做的?
思想:二人零和博弈(two-player game)
博弈双方,两个模型:
生成模型(G),判别模型(D) (分类器/网络结构)
判别模型:是一个二分类器(看作0-1二分类),用于判断样本是真是假;(分类器输入为样本,输出概率大于0.5为真,否则为假)
生成模型:是一个样本生成器,把一个噪声包装成另一个逼真的样本,使得判别器误认为是真样本;(输入为噪声,输出为样本维度相同的噪声(假样本))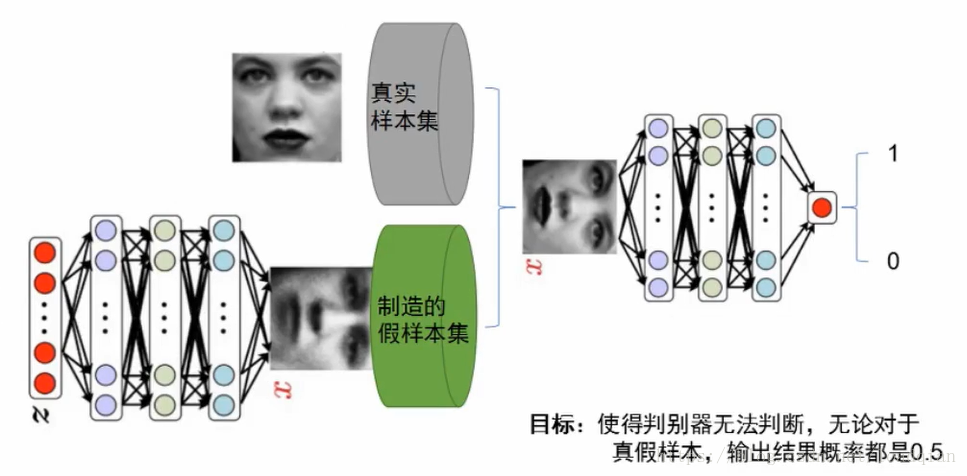
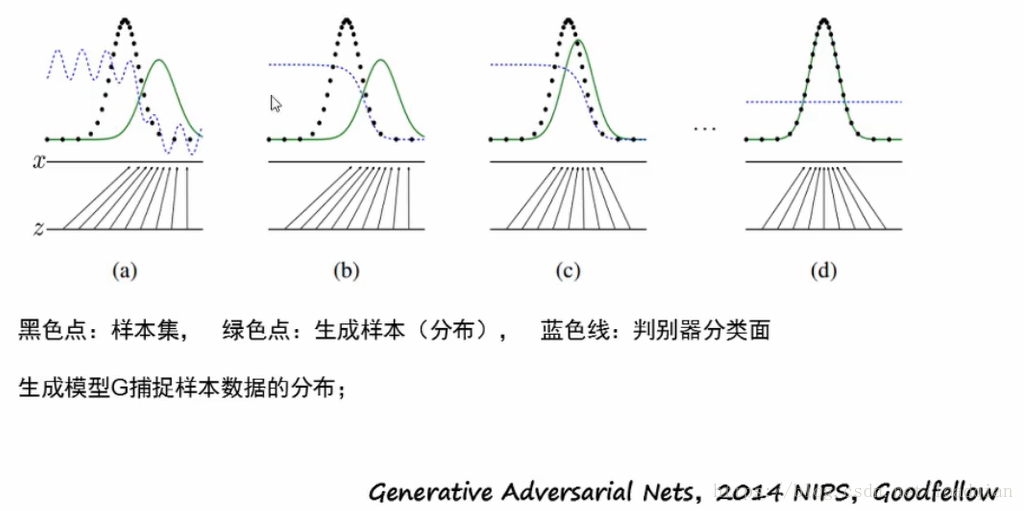
GAN是如何训练的?
几个问题:
(1)我们有什么?
有且仅有真实训练样本集,无label
(假样本集:随机制造而来,无label)
(2)无监督训练or有监督训练?
有监督,监督信号:真1假0
(3)我们的目的是什么?
生成逼真的假样本,越真越好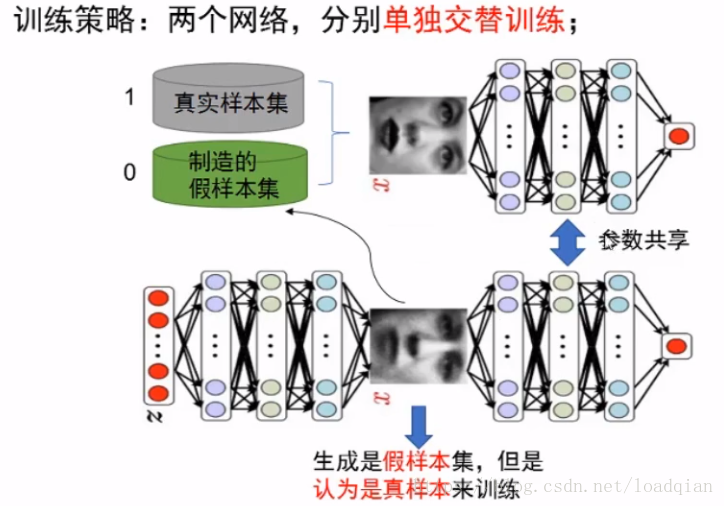
精髓:假样本在训练过程中的真假变换,这也是博弈得以进行的关键之处。
原文目标函数: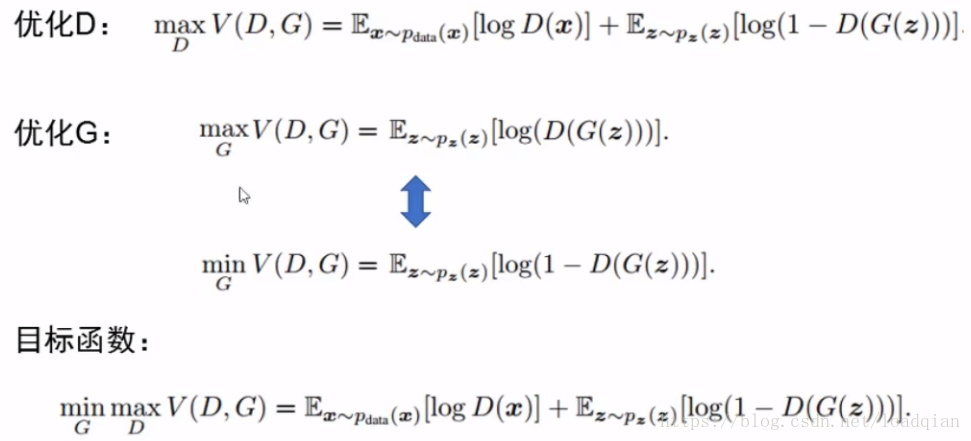
算法伪代码:
原文结论
GAN性质小结
(1)自动的学习原始真实样本集的数据分布,无需假设额外的分布模型;
(2)自动学习潜在的损失函数,判别网络潜在学习到的损失函数隐藏在网络之中;
(3)提供无监督的学习方法,无监督学习是机器学习领域的终极目标
Problem:
(1)不收敛的问题:网络不稳定,难以训练;
(2)网络需要调才能得到较好的结果,比如交替迭代次数,对结果的影响就较大
参考内容:
https://blog.csdn.net/on2way/article/details/72773771
以及他的视频分享:http://www.mooc.ai/open/course/301
论文链接:https://arxiv.org/pdf/1406.2661.pdf