介绍
识别自然图像中的文字仍是一个充满挑战的任务,本文提出了RARE(Robust text recognizer with Automatic REctification),一个对于不规则的文字具有鲁棒性的识别模型。RARE是一个深度神经网络,包括一个空间变换网络Spatial Transformer Network (STN)和一个序列识别网络Sequence Recognition Network (SRN),两个网络同时用BP算法进行训练。网络结构如下:
在测试中,一张图像先通过Thin-Plate-Spline (TPS)变换成一个正规的、更易读的图像,此变换可以矫正不同类型的不规则文本,包括透射变换和弯曲的文本。TPS变换由一组基准点(fiducial points)表示,坐标通过卷积神经网络回归得到。然后再放入SRN中进行识别。SRN使用序列识别的attention-based方法,包含一个编码器和一个解码器。编码器产生一个特征表示序列,即序列的特征向量;解码器根据输入序列循环地产生一个字符序列。这个系统是一个端到端的文本识别系统,在训练过程中也不需要额外标记字符串的关键点、字符位置等。
本文的主要贡献:1)提出了一个新颖且对不规则文本具有鲁棒性的场景文字识别方法;2)采用了基于注意力模型(attention-based)的STN框架。传统的STN只在普通的卷积神经网络中测试;3)在SRN编码器中使用循环卷积结构。
模型
模型的输入为图像I,输出为一个序列L=
(L1, . . . , LT ),Lt表示第T个字符,T为序列长度。
Spatial Transformer Network(STN)
STN使用一个预测的TPS转换将输入图像I变成矫正后的图像I’。如下图: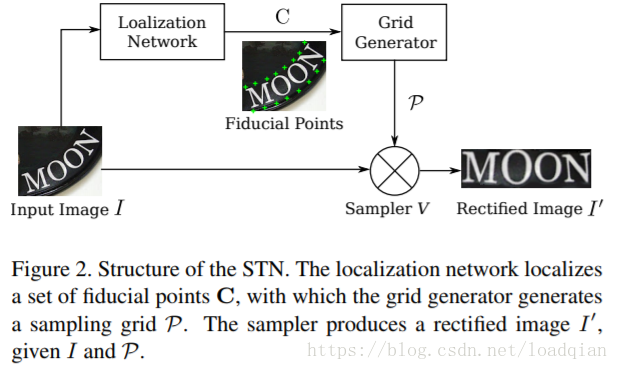
首先通过定位网络预测一组基准点,然后在网格生成器用上述基准点计算TPS变换参数,产生一个关于I的采样网格,采样器将网格和输入图像一起,通过采样网格上的点得到图像I’。STN具有一个独特的性质,即采样器是可微的,因此,一旦我们拥有一个可微的定位网络和可微的网格生成器,STN可以反向传播错误进行训练。
Localization Network
定位网络通过回归它们的x,y坐标确定了K个基准点,常数K为偶数,坐标表示为C=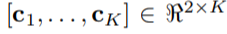
第k列ck = [xk, yk]T包含第k个基准点的坐标,我们以图像的中心作为原点构造一个归一化的坐标系,因此xk, yk的范围为[-1,1]。使用CNN来做回归,包含卷积层、池化层和全连接层,用于回归而不是分类,输出节点设置为2K,激活函数为tanh(·),输出向量(-1,1)之间。
Grid Generator
网格生成器评估TPS转换的参数并产生一个采样网格,如下图: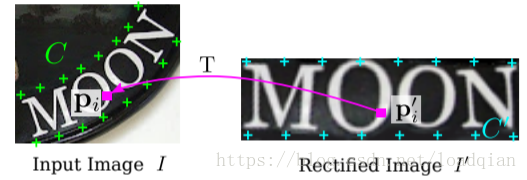
Sampler
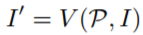
其中,V代表双线性采样器,是一个可微模型。
TPS转换的灵活性使得我们可以把多种类型的不规则文本都变得正规、可读,效果如下:
Sequence Recognition Network
SRN是一个基于注意力(attention-based)的模型,可以直接从输入图像中识别一个序列,包含一个编码器和一个解码器。编码器从输入图像I’中提取特征序列表示;解码器通过解码每一步中相关的内容来循环产生以序列表示为条件的序列。
Encoder: Convolutional-Recurrent Network
我们建立了一个结合卷积层和循环网络的结构,提取特征向量,输入图像大小可以是任意的,如下图: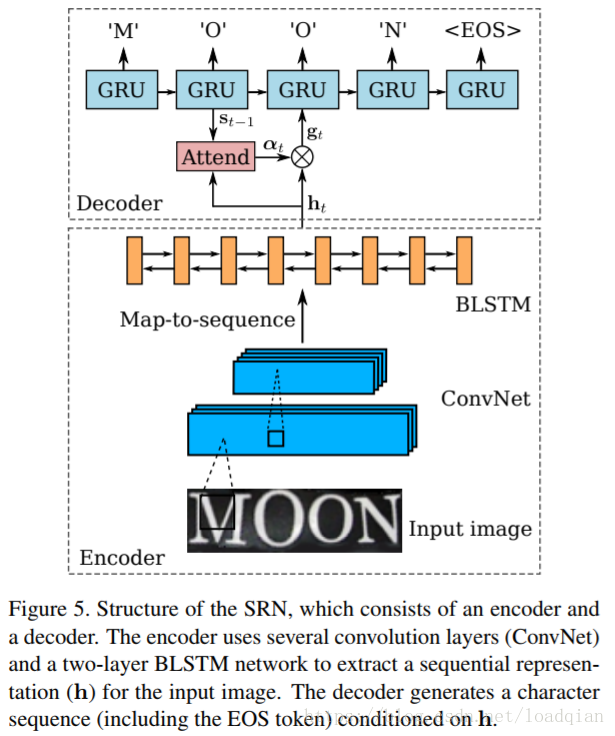
BLSTM是一个可以分析两个方向序列独立性的循环网络,它的输出是和输入大小长度相同的另一个序列h = (h1, . . . , hL),L是特征映射的宽度。
Decoder: Recurrent Character Generator
解码器以编码器产生的序列为条件生成一组字符序列,在循环部分,采用Gated Recurrent Unit (GRU)为单元。
生成包含T步,在第t步,解码器通过下式计算一个注意力权重αt ∈ RL的向量:
αt = Attend(st−1, αt−1, h) , st−1是GRU单元的上一步。当t=1时,s0、α0都是零向量。
glimpse gt与向量h线性结合: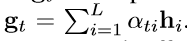
st-1通过GRU循环过程进行更新: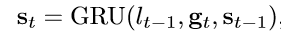
Lt-1表示训练中的第t-1个真实标签。
概率分布函数如下: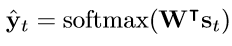
模型训练
设训练集为
优化算法采用ADADELTA,收敛速度较快。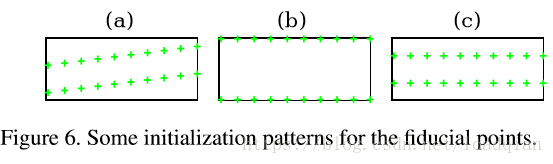
模型参数除了定位网络全连接层权值都为0,其他都随机初始化,偏差初始化为上图a的形式;经验表明,b、c初始化效果比较差。但随机初始化定位网络的参数会导致结果不收敛。
用字典进行识别
使用后验条件概率识别单词: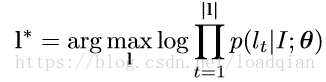
为了缩小字典集,构造前缀树,如下: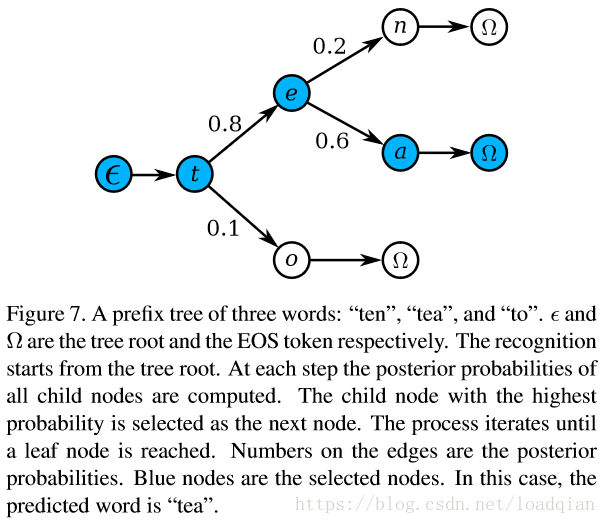
实验
参数设置
Spatial Transformer Network: STN的定位网络有4个卷积层,22max-pooling 池化层,filter、padding、stride大小分别为3,1,1;filter数量分别为64,128,256,512。卷积层和池化层后是两个全连接层包含1024个隐藏单元,基准点数K=20,要求输出40维的向量,激活函数使用RELU,除了输出层是使用tanh(·)
Sequence Recognition Network:在SRN中,编码器包含7个卷积层 ,filter大小、filter数量、stride、padding大小分别为{3,64,1,1}, {3,128,1,1}, {3,256,1,1}, {3,256,1,1,}, {3,512,1,1}, {3,512,1,1},{2,512,1,0}. 第1、2、4、6个卷积层后分别连接22的max-pooling。在卷积层上是两层带256个隐藏单元的BLSTM网络。对于解码器,GRL单元有256个记忆模块和37个输出单元(26单词、10数字和1EOS)
Model Training :8百万合成样本,batch size=64,图像大小为 100×32 ,STN中输出的图像大小也为100×32
不同基准的实验结果
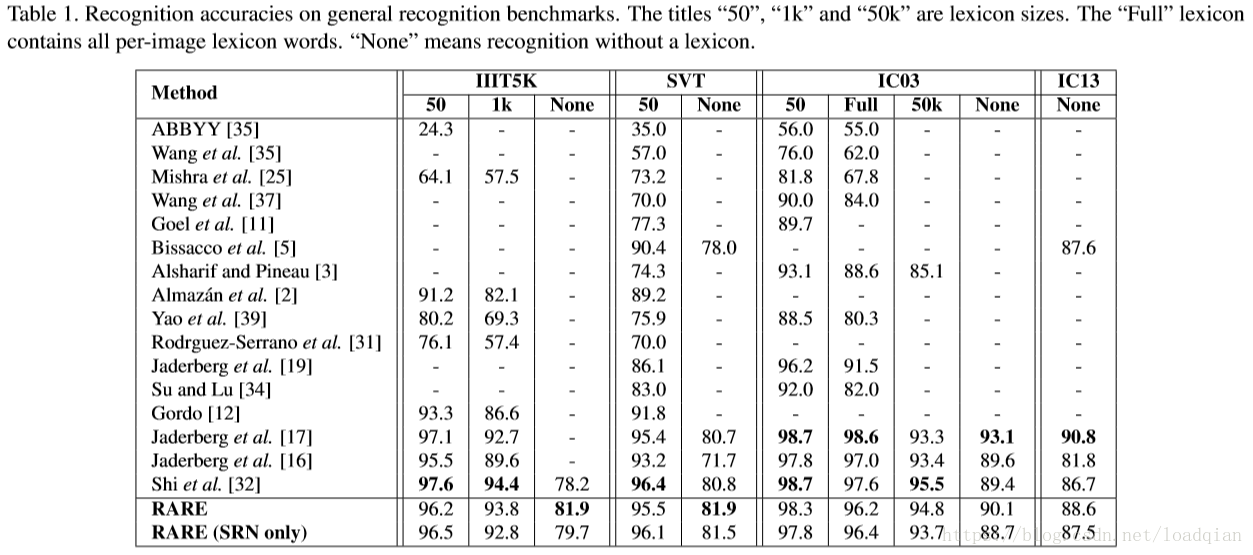
识别投射文本

SVT-Perspective 是用于投射文本识别的算法,并与其他方法进行对比,结果如下: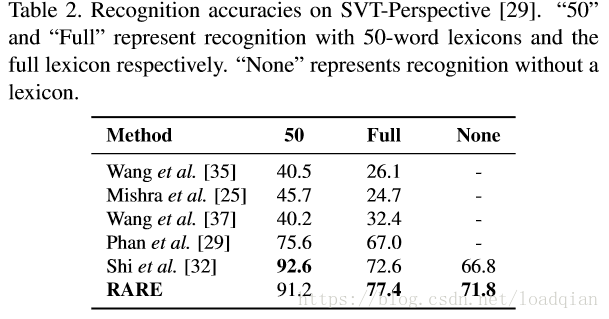
识别变形的文本

CUTE80用于识别变形的文本,与其他方法进行对比,结果如下:
结论
为了解决不规则文本的识别,采用了一个可微的空间转换网络(spatial transformer network),此外,它还与基于注意力学习的序列识别结合,使得整个模型可以端到端进行识别。实验结果表明:1)在没有几何监督的前提下,这个模型能自动产生可读性更强的图像;2)本文提出的图像矫正模型能提高识别精确度;3)本文提出的识别系统与现有方法相比结果更好。
原文链接:
https://arxiv.org/pdf/1603.03915.pdf