论文链接:http://openaccess.thecvf.com/content_cvpr_2018/papers/Chen_Deep_Photo_Enhancer_CVPR_2018_paper.pdf
实验demo:
http://www.cmlab.csie.ntu.edu.tw/project/Deep-Photo-Enhancer/
人生总是奇妙的,一旦你努力去做一件事,如果结果不是你想象的那样,那么老天一定会给你一个更好的结果。(鸡汤)
摘要
本文提出了一种非配对学习的方法用于图像增强。给定一组具有所需特征的照片,本文的方法是学习一个增强器,将输入图像转化为具有这些特征的增强图像。
该方法基于two-way generative adversarial networks (GANs)并作了三方面的改进:
- 扩展了U-Net,加入全局特征global features,作为生成器;
- 用自适应的权值改进了Wasserstein GAN (WGAN),与WGAN-GP相比,其训练收敛更快、更好,且对参数不敏感;
- 在two-way GANs的生成器中使用individual batch normalization层,使得生成器更好地适应各自的输入分布。
介绍
图像增强方法试图解决色彩再现和图像清晰度的问题,目前有很多交互式的工具和半自动的方法,如直方图均衡、锐化、对比度调整、颜色映射等,甚至一些改进的方法,如局部和自适应性调整,都没有取得较好的效果。
本文提出的方法通过学习大量照片来进行图像增强,其输入只需要一系列具有所需特征的“good”照片。因此,图像增强问题看成是将输入图像转化为在训练照片集中嵌入所需特征的增强图像,采用类似于CycleGAN的two-way GAN结构来解决这个问题,由于GAN的训练具有不稳定性,我们做了一些改进:
- 扩展了U-Net,加入全局特征global features,作为生成器,这些全局特征可以捕捉场景设置,全局亮度甚至主题类型的概念,对局部操作有跟大帮助;
- 用自适应的权值改进了Wasserstein GAN (WGAN),WGAN使用权值clipping强制满足Lipschitz约束,也有方法加入了gradient penalty来满足上述约束,但这些方法对参数很敏感,因此我们提出权值自适应性来改进WGAN的训练收敛性;
- 大多数two-way GANs结构在前向和后向过程中都使用相同的生成器,但我们发现生成器的输入实际上来自不同的数据源,前者为输入数据,后者为生成的数据,他们分布的差异性会对生成器产生严重影响,因此我们对生成器使用individual batch normalization层,使得生成器更好地适应各自的输入分布。
基于这些改进,我们的方法得到了高质量的增强图像,与之前的方法相比结果更自然,此外,本文提出的global U-Net, adaptive WGAN 和 individual batch normalization在其他应用上也取得了不错的效果。
概述
我们的目标是得到照片增强器\(\Phi \),输入图像\(x\)得到增强后的图像\(\Phi (x)\)。由于人类感知的复杂性和主观性,很难去定义增强,在本文中我们用一组样例\(Y\)来定义增强。本文提出的方法旨在找出这些图像\(Y\)中的共同特征并得到增强器,因此增强后的图像\(\Phi (x)\)既具有所需特征有保留了原始图像\(x\)的内容。
GAN模型包含一个生成器G和一个判别器D,常被用于处理图像转化问题,将输入图像从源域\(X\)转化到目标域\(Y\)的输出图像,这里源域\(X\)表示原始图像,目标域\(Y\)为具有所需特征的图像。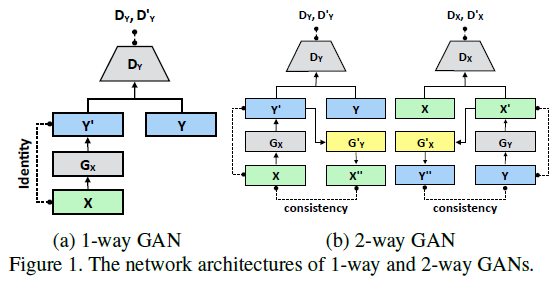
图1(a)为1-wayGAN结构,给定输入\(x \in X\),经过生成器\({G_X}\)后\(x\)转化为\(y’ = {G_X}(x) \in Y\);判别器\({D_Y}\)主要用以区分样本是目标域\(\{ y\} \)还是生成器生成的\(y’ = {G_X}(x)\)。本文中,使用循环一致性来获取更好的结果,采用了类似CycleGAN和DualGAN的2-way GANs结构,生成器\({G_Y}’\)将\({G_X}\)生成的样本重新映射到源域\(X\),即\({G_Y}’({G_X}(x)) = x\)。此外,2-way GANs中通常包含一个前向映射\(X \to Y\)和一个后向映射\(Y \to X\),如图2(b)。在前向传递中,\(x \to y’ \to x’’\),判断\(x\)和\(x’’\)的一致性;在后向传递中,\(y \to x’ \to y’’\),判断\(y\)和\(y’’\)的一致性。
生成器
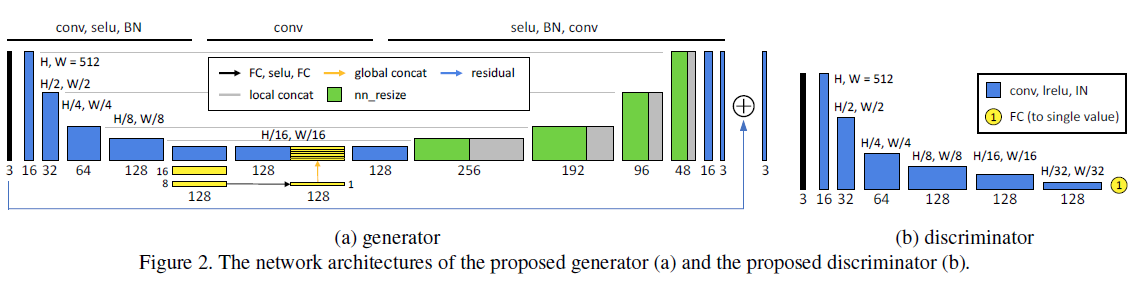
图2(a)为生成器的网络结构,输入图像大小为\(512 \times 512\).
本文中,生成器基于U-Net,最初用来处理生物医学分割问题,之后在许多其他任务中展示了强大性能,但在我们的任务中并没有取得较好的效果,可能是因为U-Net中不包含全局特征,全局特征包含高层次的信息,如场景分类、主题类型、全局亮度等,对独立像素的局部调整意义重大,因此我们在U-Net中引入全局特征。
为了提高模型效率,全局和局部特征的提取使用相同的U-Net收缩部分前五层。每个收缩步骤(contraction step)包含\(5 \times 5\)的滤波器,步长为2,SELU为激活函数和批处理归一化(batch normalization)。对于全局特征,网络第5层中,给定\({\rm{32}} \times {\rm{32}} \times {\rm{128}}\)的feature map,使用上述收缩算法减少到\({\rm{16}} \times {\rm{16}} \times {\rm{128}}\)再到\({\rm{8}} \times {\rm{8}} \times {\rm{128}}\),经过一个全连接层再减少到\({\rm{1}} \times {\rm{1}} \times {\rm{128}}\),之后接着一个SELU激活函数层和一个全连接层。将\({\rm{1}} \times {\rm{1}} \times {\rm{128}}\)的全局特征复制\(32 \times 32\)串联在\({\rm{32}} \times {\rm{32}} \times {\rm{128}}\)的低层特征(low-level features)之后,构成了包含全局和局部特征的\({\rm{32}} \times {\rm{32}} \times {\rm{256}}\)的feature map,随后执行U-Net的扩展路径(expansive path),最后加入残差学习。也就是说,生成器只学习了输入图像和标签图像之间的差异。
数据集:MIT-Adobe 5K dataset,包含5000张使用全局和局部调整润饰过的图像。数据集分为三部分:2250张图像和其对应的润饰过的图像用于这部分的监督训练,作为源域;剩余的2250张润饰过的图像用于第5部分和迪第6部分的非配对学习,作为目标域;最后的500张图像用于测试。
实验:评估了生成器的以下几个网络结构:1)DPED:选择该网络中的GAN结构进行评估;2)8RESBLK:这个生成器用于CycleGAN和UNIT;3)FCN:全连接卷积网络用于滤波器近似;4)CRN:该结构用于从语义标签中合成真实图像;5)U-Net。在上述结构中都加入了残差学习。
损失函数用来最大化PSNR: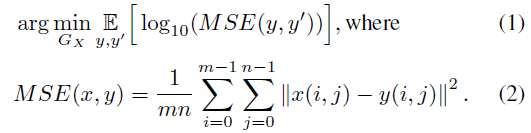
表1,表2分别比较了这些不同的结构,实验表明,本文中提出的全局U-Net结构取得了最好的效果。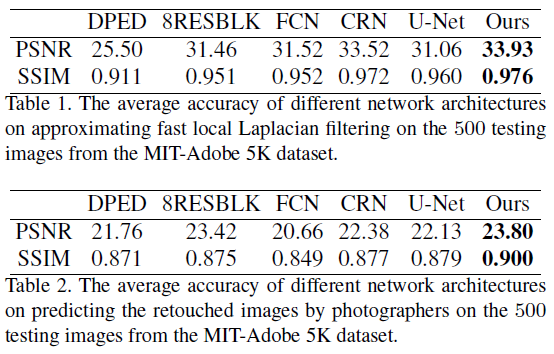
One-way GAN
本部分主要介绍基于GAN结构的非配对训练,将图2(a)中的生成器和图2(b)中的判别器带入图1(a)中就可以得到1-way GAN,将其与一些其他的GANs如:GAN,LSGAN,DRAGAN and WGANGP,设置不同的参数进行比较,得到如下结果: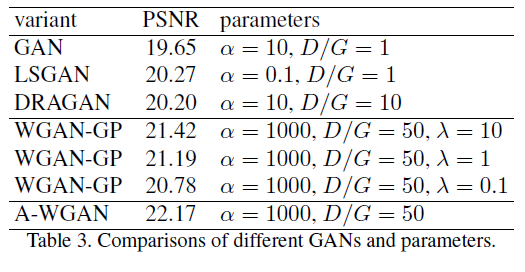
从表3中可以看出,WGAN-GP的效果依赖于额外的参数\(\lambda \),用于加权梯度惩罚(weight the gradient penalty)。参数\(\lambda \)的选择比较重要,在本文中,我们使用如下梯度惩罚因子: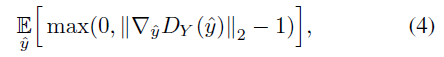
上式很好地反映了Lipschitz约束,要求梯度小于等于1,因此只惩罚大于1的部分。此外,我们引入了自适应权值方案来调整权值\(\lambda \),使梯度落在想要的范围内,即\([1.001,1.05]\)。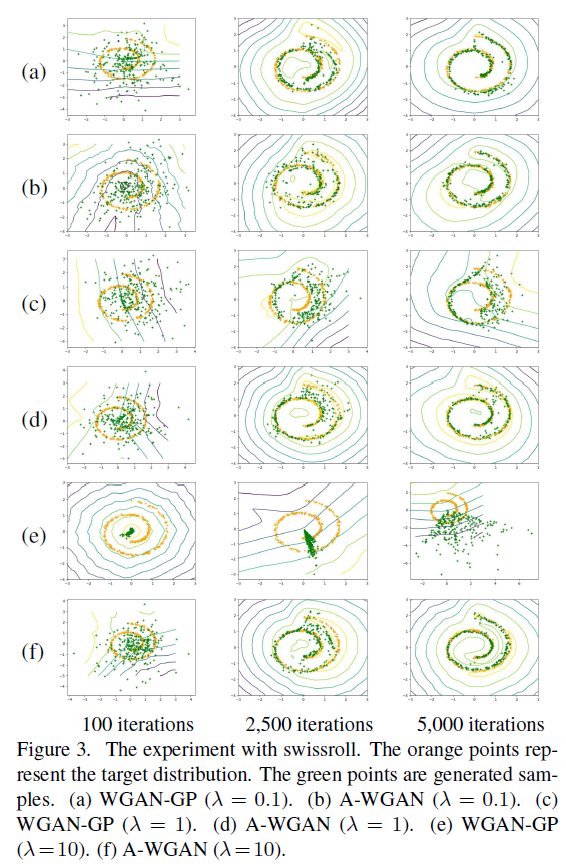
图3比较了在swissroll dataset上WGAN-GP和本文中提出的AWGAN,可以看到不管初始化\(\lambda \)为多少,AWGAN都收敛于目标分布;然而WGAN-GP很依赖\(\lambda \)。表3也证明了A-WGAN优于WGAN-GP并取得了最好的结果。
Two-way GAN
为了得到更好的实验结果,引入2-way GAN。下表4比较了2-way GAN结构的WGAN-GP和A-WGAN,然而WGAN-GP的增长更大,这可能是因为A-WGAN改进空间比较小。
大多数two-way GANs结构在前向和后向过程中都使用相同的生成器,但我们发现生成器的输入实际上来自不同的数据源,前者为输入数据,后者为生成的数据,他们有不同的分布特征,因此我们对生成器使用individual batch normalization(iBN)层,使得生成器更好地适应各自的输入分布。
表4,验证了加入了individual batch normalization的生成器能适应输入分布WGAN-GP和A-WGAN的结果分别提高了0.31dB,0.16dB,图4中也可以看到,若没有iBN,2-way GAN就不能得到正确的分布。
总的来说,我们的网络包含多个损失:
1.恒等映射损失(identity mapping loss):为了保证变换后的图像\(y\)与输入图像\(x\)内容的一致性,由于是2-way GAN,同样有相应的映射从\(y\)到\(x’\),如下: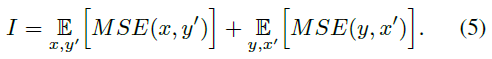
2.循环一致性损失(cycle consistency loss),如下: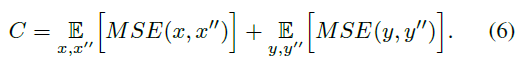
3.生成器和判别器的对抗损失(adversarial losses),如下: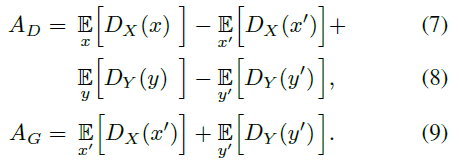
训练判别器时,梯度惩罚(gradient penalty)P为: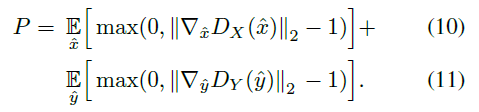
上式满足了Wasserstein距离的1-Lipschitz functions,因此判别器用下式进行优化: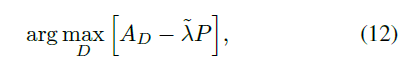
其中,\(\widetilde \lambda \)是由A-WGAN自适应调整得到的。
生成器由下式得到: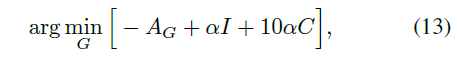
其中,\(\alpha \)为对抗损失和恒等/一致性损失的权重,最终我们将生成器\({G_X}\)作为照片增强器\(\Phi \)。
结果

图4展示了我们的模型与一些其他模型的对比,可以看到,经过MIT-Adobe 5K 数据集上的学习,我们的监督方法(d)和非配对学习方法(e)都对输入图像进行了合理的增强。在收集到的HDR数据集上训练后的模型结果(b)在所有的方法中取得了最好的结果。
局限性:若输入图像较暗或者包含大量噪声,我们的模型会放大噪声。此外,由于一些用于训练的HDR图像是色调映射的产物,所以我们的模型可能会继承色调映射的光环效应。
其他应用 :本文中提出了三个改进:global U-Net, adaptive WGAN (A-WGAN)和
individual batch normalization (iBN)。
- 对于global U-Net,将其运用到宠物的三元图分割,使用Oxford-IIIT Pet dataset。U-Net和global U-Net的准确率分别为0.8759和0.8905,结果如图7第一行。
- 对于不用的\(\lambda \),WGAN-GP的结果时好时坏,但本文提出的A-WGAN几乎不依赖\(\lambda \),且对三个不同的\(\lambda \)都取得了较好的结果(这里只列出一个),如图7的第二行展示了卧室图像合成的结果。
- 将2-way GAN运用到人脸性别转换,如图7最后一行所示,2-way GAN的效果比较差,但引入了本文提出的iBN取得了较好的结果。

总结
本文提出了一个深度图像增强器,从一系列包含所需特征的照片中进行学习用于图像增强,这是一种非配对的过程,所以收集训练图像比较容易。本文的三大改进:global U-Net, adaptive WGAN (A-WGAN) 和 individual batch normalization (iBN)对后续的研究和应用有着重要的意义。