介绍
这篇论文最大的贡献之一就是提供了一个真实世界的低光照图像和对应reference的数据集,但这些图像不是传统的类型,属于raw sensor data,低光照图像是短曝光下得到的,对应的ref为长曝光,SID数据集总共包含5094对。图像由两部相机Sony α7S II 和Fujifilm X-T2拍摄得到,其对应的传感器分别为Bayer和X-Trans,得到的图像分辨率为4240×2832和6000×4000。
本文提出了一个端到端的网络结构,直接处理低光照的raw data,包括色彩变化、去马赛克、减少噪声和图像增强,网络结构如下: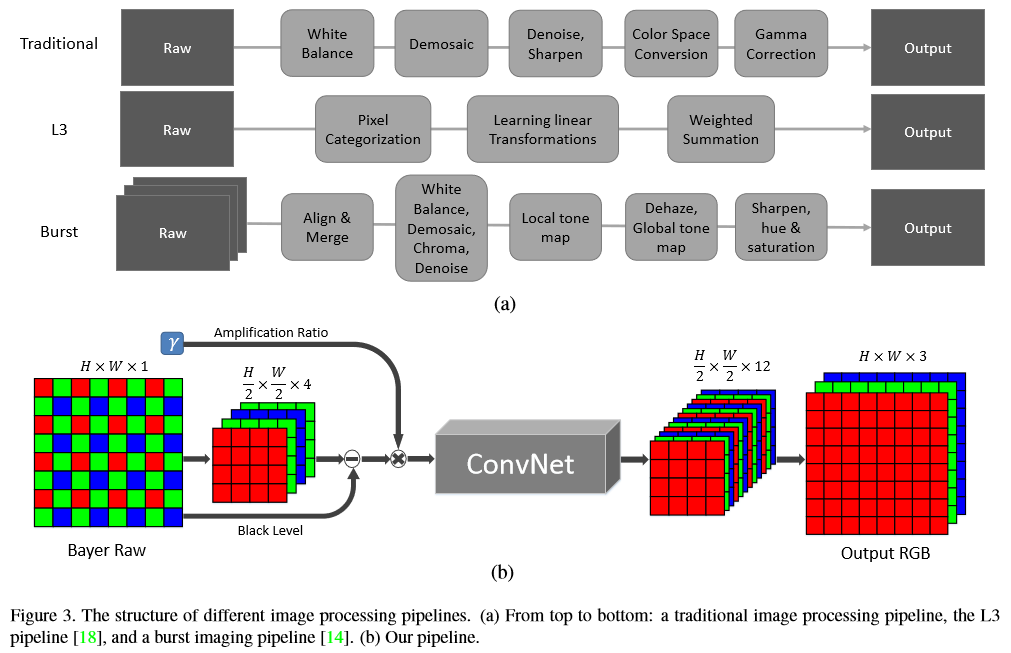
(a)为传统的图像处理流程,如白平衡、去马赛克、去噪、锐化、颜色空间转换、gamma变化等,这些一般针对特定的相机,泛化性能比较差,而且不能很好地处理极度低的SNR。(b)是本文中提出的结构,对于Bayer arrays把输入pack成4通道,对应的分辨率变为原来的一半;对于X-Trans arrays,输入为6/*6的block, pack成9通道(这里不太懂这个预处理有什么特殊目的)。之后减去black level再乘上期望的放大因子,得到的图像作为网络的输入,默认使用U-Net结构,网络的输出为12通道、原图一半空间分辨率的如下,再经过sub-pixel层复原到全分辨率大小,且输出为RGB空间。
网络使用L1loss,每个相机单独训练一个网络。由于低曝光图像往往带有噪声,所以作者还对比了一些去噪方法。部分实验结果如下:
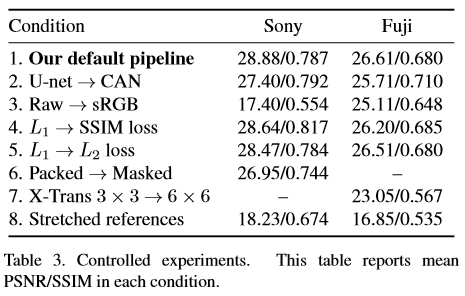
总结
虽然本文的结构在SID数据集上有效抑制了噪声且得到了正确的色彩变换,但还是存在一些问题,如:SID数据集比较有限,不包含人像或者动态目标,不能处理HDR色调映射;实验结果存在一些伪影;提出的框架中放大因子需要在外部选择好输入;对每一种相机的传感器要单独训练一个网络,泛化能力比较差;处理图像的速度不够快,不能实现实时图像增强,这些都需要在后续的研究中继续加以改进。