这篇论文主要介绍了两篇做低光照视频增强的论文,两篇论文都提出了成对的数据集。
Learning to See Moving Objects in the Dark(ICCV2019)
这篇文章的主要贡献有:①建立了一个新的共轴光学系统来捕获时间同步和空间对齐的低光和光线充足的视频对;②提供了第一个包含动态车辆和行人的街景低光/正常光视频数据对;③采用3Dconv和2D pooling/deconv相结合的改进UNet结构作为框架用于低光照视频增强,在色彩保真度和时间一致性上表现出卓越的性能。
摄像系统结构如下: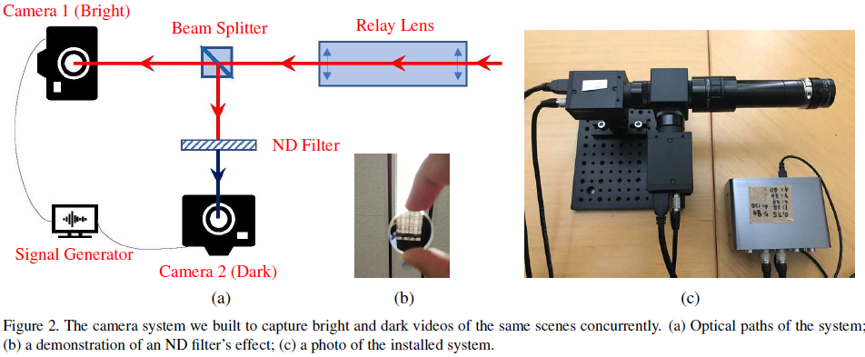
网络结构如下: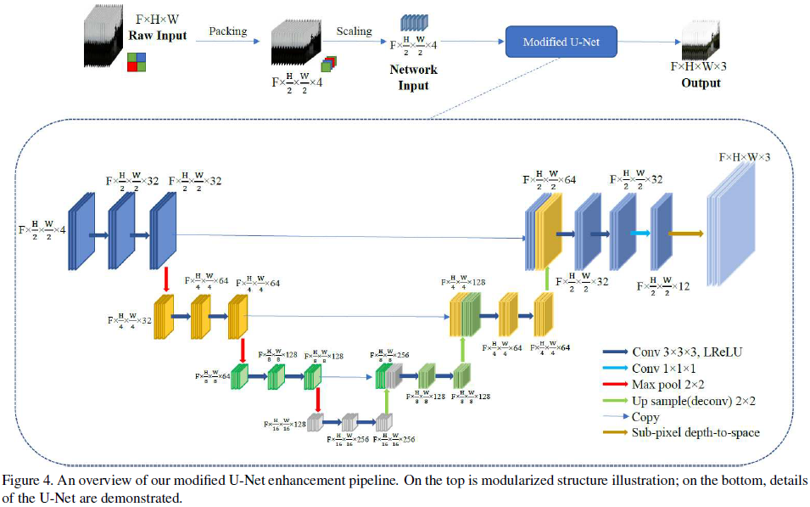
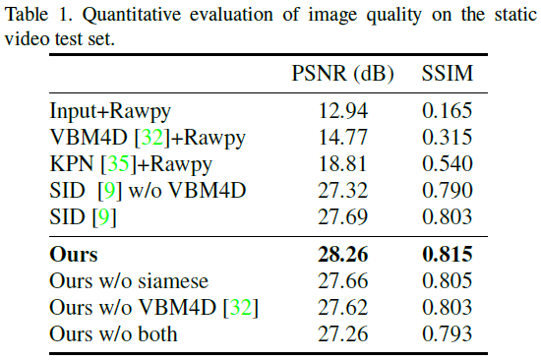
部分实验结果如下:
Seeing Motion in the Dark (ICCV2019)
这篇论文跟2018年CVPR See in the dark是同一个作者写的,SID做的是低光照图像增强,本文中做的是视频的增强。主要动机是:极端低光照的视频处理仍是一个棘手的问题,因为很难收集到对应GT的视频数据。这篇文章的主要贡献有以下两点:①提出了一个极端低光照下的静态视频及对应的GT数据对Dark Raw Video(DRV) dataset,另外还拍摄了真实的动态低光照视频(无GT)用于测试;②设计了一个深度Siamese网络和特定的loss函数用于保证时间和空间稳定性和一致性。该网络在静态数据集上训练且可以扩展到动态视频处理中,并取得SOTA的结果。网络结构如下: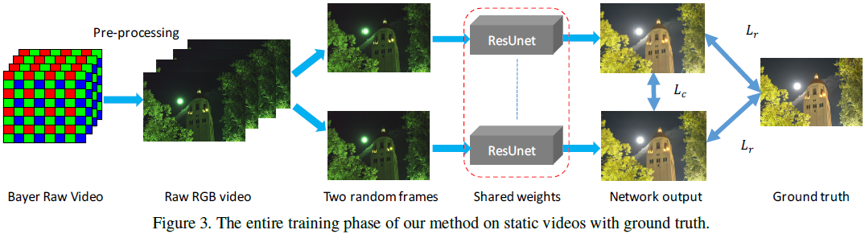
网络的结构设计还是比较简单的,但要注意其中一些细节并没有展示出来。第一阶段的预处理,包含了Bayer到RAW RGB图像的转换、block level subtraction、binning and global digital gain以及VBM4D等用于去除噪声。网络的输入是从一个静态序列中随机采样两帧,分别得到两个结果计算loss,除了重建loss之外,这里还引入了自身一致性损失,也就是保证输出的两帧结果在特征空间上的一致性,为了避免逐帧闪烁。Loss函数如下: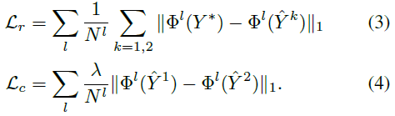
具体的实验细节就不赘述了,给出部分实验结果: