本文主要用于介绍经典的空间转换网络,并将这种思想运用到了超分辨中的一篇论文。
Spatial Transformer Networks (CVPR2016)
本文提出了一个独立的神经网络模块,空间变换网络,可以直接加入到已有的CNN或FCN中对数据进行空间变换操作。它不需要关键点的标定,能够根据分类或者其他任务自适应地将数据进行对齐或空间变换(包括平移、缩放、旋转以及其他几何变换),从而减少由于物体变换对任务的影响,提升网络的学习能力。
整个空间变换器包含三个部分,本地网络(Localisation Network)、网格生成器(Grid Genator)和采样器(Sampler),如下: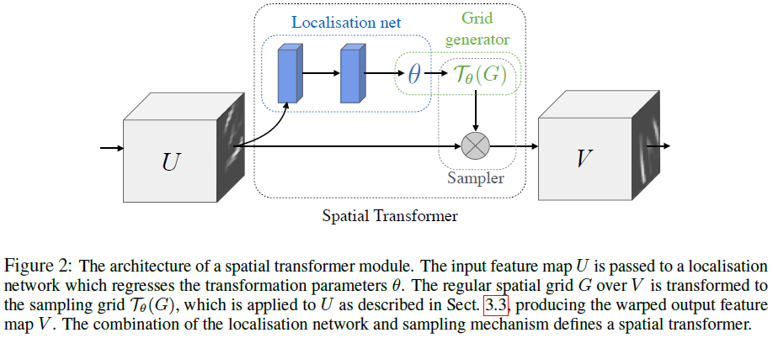
本地网络通过一个子网络(全连接或卷积网络,再加上一个回归层)用来生成空间变换的参数θ,θ的形式可以多样,如需实现2D仿射变换,θ 就是一个6维(2x3)向量的输出。网格生成器用来得到U和V各位置的对应关系: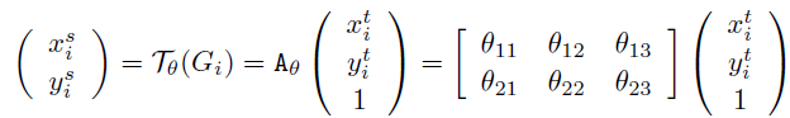
采样器也有多种形式,为了使得loss可以反向传播,这里用双线性插值核来进行采样,表达式及求导过程如下: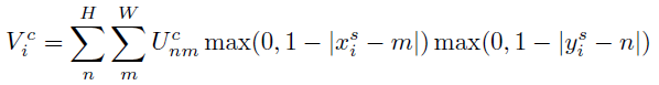
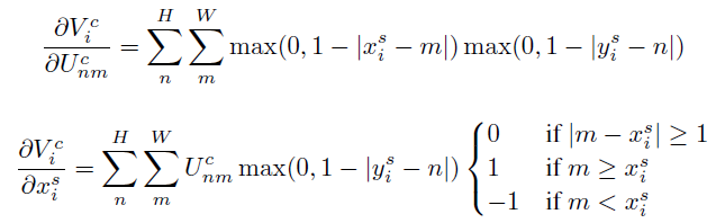
本文在手写文字识别、街景数字识别、鸟类分类以及共定位等方面做了实验, 这里只列出比较有代表性的手写文字实验部分。实验数据为MNIST,分别在经过不同处理(包括 旋转(R)、旋转、缩放、平移(RTS),透射变换(P)),弹性变形(E))的数据上进行字符识别的实验。Baseline分别使用了两种网络结构FCN , CNN, 加入了 STN 的网络为 ST-FCN, ST-CNN。其中,STN 采用了以下几种变换方法:仿射变换(Aff )、透射变换(Proj )、以及薄板样条变换(TPS )。左边表列出了 STN 与 baseline 在MNIST上的比较结果,表中数据为识别错误率。右边图中可以看出,对不同的形式的数据,加入了STN 的网络均优于 baseline 的结果。以下为 STN 对数字图像进行变换后的结果,其中a列为原始数据,b列为变换参数的示意图,c列为最终变换后的结果。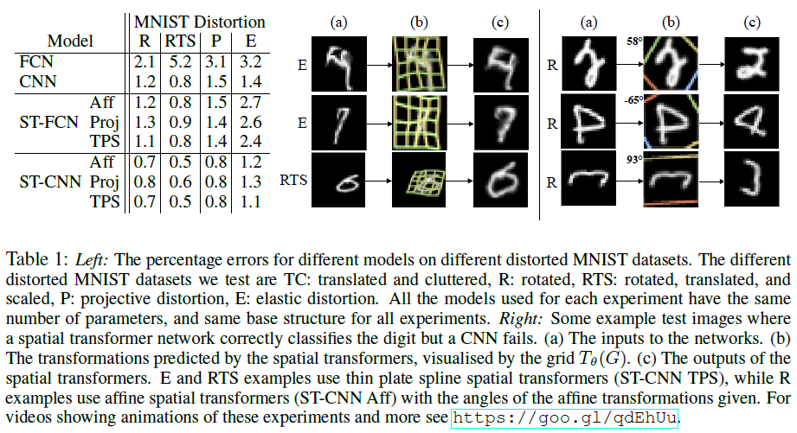
Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform (CVPR2018)
这篇论文主要论述了语义分割图作为分类先验在SR约束似然解空间中的作用。简单的说就是想用图像的类别信息做指导,来复原更真实、自然的纹理。这种先验也可以其他的,比如图像深度。这里作者使用语义分割map作为分类先验,以此为条件,通过一个空间特征转换层生成一对修正参数,将单个网络中一部分中间层的特征作仿射变换,从而更好地复原纹理信息。其网络结构如下: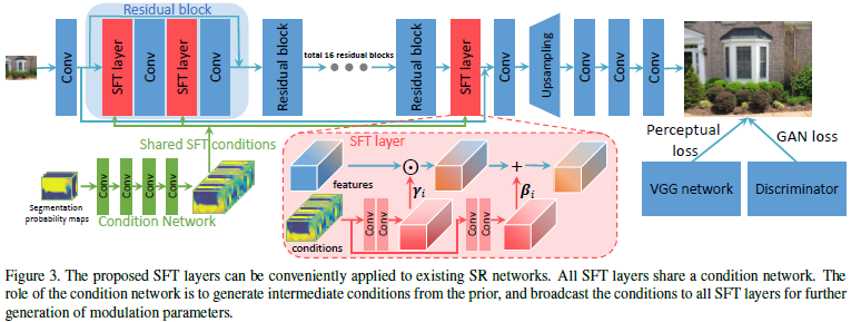
部分实验对比图如下: