摘要
训练一个庞大的深层卷积神经网络,将ImageNet LSVRC-2010比赛中的120万张1000种不同类别的高分辨率图像进行分类。在测试数据上,top-1和top-5的误差率分别为37.5%和17%,这比以往的先进水平都要好得多。它具有6000万个参数和650,000个神经元,该神经网络由五个卷积层,其中一些有池化层,和三个全连接层且有1000-way的softmax回归模型。使用非饱和神经元和GPU加速加快训练速度,并采用dropout正则化方法来减少全连接层中的过拟合,取得了不错的实验效果。同时,在ILSVRC-2012比赛中加入了该模型的一个变式,以15.3%的top-5误差率胜过第二的26.2%。
介绍
本文的具体贡献如下:我们训练了一个最大的卷积神经网络来训练在ILSVRC-2010和ILSVRC-2012中使用的ImageNet中的子集,并取得了迄今为止最好的结果。我们使用高度优化的GPU实现二维卷积和一些其他固有的方式来训练卷积神经网络,并将其公开。在第3部分介绍了减少训练时间、提高性能的方法;在第4部分介绍了减少过拟合的方法;最后的神经网络由5个卷积层和3个全连接层,其深度至关重要,移除任意一个卷积层会使结果表现不佳。
数据集
ImageNet是一个包含超过1500万张带标签的高分辨率图像的数据集,大约有22,000个类别。从2010年开始,作为Pascal视觉对象挑战赛的一部分,每年都会举办一场ImageNet大规模视觉识别挑战赛(ILSVRC)。ILSVRC使用ImageNet的一个子集,包含1000种类别,每种类别1000张图像。 总共大约120万张训练图像,50,000张验证图像,以及150,000张测试图像。
在ImageNet上,我们往往使用两种误差率,top-1和top-5,其中 ,top-5是指测试图像上正确标签不属于模型认为最有可能的五个标签的百分比。
架构
ReLU 非线性变换
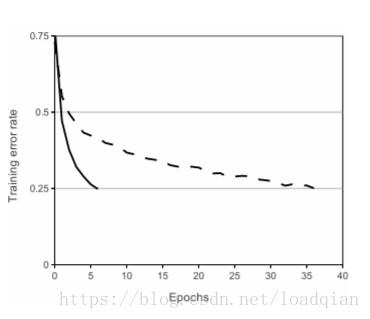
从图中可以看到,具有ReLUs(实线)的四层卷积神经网络在CIFAR-10上epoch=5时就把训练错误率降到25%,比tanh(虚线)的等效网络快六倍左右。 每个网络的学习率都是独立选择的,以尽可能快地进行训练。,没有采用任何形式的正则化。 这里展示效果会随网络架构而变化,但具有ReLUs的网络比其他同等饱和神经元的速度快好几倍。
相比于Sigmoid和Tanh激活函数,ReLU激活函数能极大加速随机梯度下降法的收敛速度,而且不存在梯度消失的问题。
多GPU训练
120万的训练样本过于庞大,所以使用两个CPU并行处理,它们可以直接读取和写入彼此的内存,而不需要通过主机内存。这种并行化机制将每个内核(或神经元)的一半各放在两个GPU上,另外还有一个技巧是GPU只在某些层进行通信。如,第3层的内核从第2层的所有内核映射中获取输入。但第4层的内核只从属于同一GPU上的第3层内核映射中获取输入。 选择连通性模式是交叉验证的问题,但这使我们能精确调整通信量,直到计算量能被我们接受。
局部响应归一化
ReLUs具有理想的属性,不需要输入归一化来防止饱和,局部归一化有助于模型的泛化。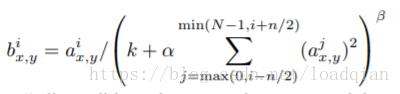
其中,a_(x,y)表示点(x,y)处运用卷积和ReLU非线性后的结果,b_(x,y)是响应归一化的结果,其总和在相同空间位置处的n个“相邻”核映射上运行,n是该层的映射总数。内核映射的排列顺序是任意的,且在训练开始前就确定好了。这种响应归一化实现了实现了一种由真实神经元中激发的侧抑制,在使用不同内核计算的神经元输出之间创造竞争环境。将剩余的参数设置成确定的超参数n=5,k=2,alpha=10^-4,beta=0.75。
重叠池化
CNN中的池化层汇总了相同内核映射中相邻神经元组的输出。通常通过相邻池化单元汇总使得邻近关系不重叠。准确地说,一个池化层可以被认为是由一个间隔为s个像素的池化单元组成的网格,每个都以池化单元的位置为中心的大小为z×z的邻域。如果s=z,就是CNN中传统的局部池化;如果s<z,我们可以得到重叠池化,与s=2,z=2相比,令s=2,z=3可以使top-1,top-5分别下降0.4%和0.3%。同时,在训练过程中可以发现,重叠池化较难产生过拟合。
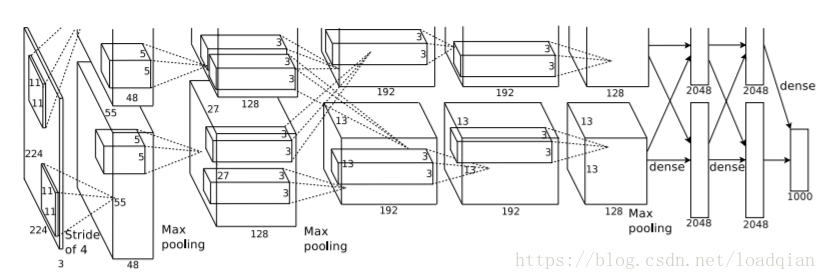
整体结构
减少过拟合
数据增广
减少过拟合图像数据的最简单、最常用的方法是使用标签保留转换。我们采用两种不同形式的数据增广,这两种形式都允许通过很少的计算从原始图像产生变换后的图像,所以变换后的图像不需要存储在磁盘上。在实现的过程中,转换后的图像是在CPU上的用Python生成的,而GPU正在训练上一批图像因此,这个数据增广方案实际是计算上免费的。
第一种形式包括生成图像转换和水平翻转。在256256图像中随机提取224\224块(及其水平翻转),用这些块在网络中训练,因此输入数据为224*224*3,使训练规模扩大了2048倍,有效防止了过拟合。在测试时,通过提取5个224×224块(四个角和中心)以及它们的水平翻转(共计10个块)来进行预测,用softmax层来预测它们的平均值。
第二种形式是改变图像中RGB通道的强度。在整个ImageNet训练集的RGB像素集上执行PCA,对每个训练图像,成倍增加已有主成分,比例大小为对应特征值乘以一个从均值为0、标准差为0.1的高斯分布中提取的随机变量。这个方案表现了自然图像的重要属性,即物体的属性是不会随光照强度和颜色变换而变化的,该方案使top-1误差率降低1%以上。
dropout
dropout技术是以一定概率将每个隐层神经元的输出置为零。以这种方式 “dropped out” 的神经元既不会前向传播,也不参与反向传播,所以每进行一次迭代,神经网络就尝试一个不同的结构,但是所有这些结构之间共享权重。由于神经元不能依赖于其他特定神经元而存在,所以这种技术降低了神经元复杂的互适应关系。因此,网络被迫学习更具有鲁棒性。在测试时,将所有神经元的输出乘以0.5,这对于采用指数衰减网络产生的预测分布的几何平均数是一个合理的近似。
学习过程
本文采用了随机梯度下降法(SGD)和一批大小为128、动量为0.9、权重衰减为0.0005的样例来训练网络,更新权重方式如下:
i是迭代次数,v是动量
用一个均值为0、标准差为0.01的高斯分布初始化了每一层的权重w,第二、第四和第五个卷积层以及全连接隐层的神经元偏置b都初始化为常数1,其余层的偏置b设为0。所有层都使用相同的学习率,在训练过程中手动调整,当验证错误率以当前学习率停止改进时,将学习率除以10。学习率初始化0.01,在终止前减少三次。使用这个网络对120万张图像进行了约90次的训练,需要在NVIDIA GTX 580 3GB GPU上花费了五到六天时间。
结果
实验结果如下: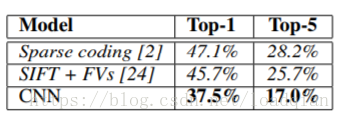
本文的创新点:
1.使用两个GPU并行加速处理
2.使用ReLU作为激活函数
3.采用dropout正则化和data augmentation来防止过拟合
4.使用深度卷积神经网络(5个卷积层和3个全连接层)