介绍
在本文中,我们试图改进对LSTMs的科学理解,特别是语言模型和LSTM中存在的字形模型之间的相互作用。 我们称这种内部语言模型为隐式语言模型(隐式LM)。 本文的贡献:1)在受控条件下建立隐式LM的存在; 2)通过找出它使用的上下文有多少个字符来描述隐式LM的本质。 我们所描述的隐式LM与上面讨论的文献19、20中的语言模型有所不同,因为学习语言模型的背景和要求不同:OCR明确要求学习字形模型而不是语言模型。最近的关于使用LSTM进行OCR的基准文件22并没有涉及这一点,而且据我们所知,文献中也没有涉及。
实验准备
A.数据
我们执行的实验需要固定长度序列的受控数据集,并具有特定的要求,这些要求很容易从合成图像中创建,但难以在现实世界的数据中找到。 幸运的是,我们的目标是提高对LSTM的理解,而不是直接影响性能的提高,因此并不明确要求真实世界的数据。 在手写图像数据集上使用合成图像具有消除图像背景噪声干扰实验结果的优势。
训练集包含6种字体,字体大小8-16,选取32180个独特的句子。验证图像选取1585个独特的句子,与训练集以相同的方式呈现,并具有相同的字体。我们选择不同于训练字体的测试字体,并且具有足够大的误差以便可测量。用于测试的训练字体给出接近0%的误差。
B.预处理
为确保模型具有恒定的输入尺寸,将图像缩放到30像素的恒定高度,同时保留宽高比。如文献23中所建议的那样,将它们归一化为均值为0和标准差为1。
C.模型
Image–>分割–>FC–>ReLU–>FC–>ReLU–>LSTM–>LSTM–>FC–>Softmax–>CTC loss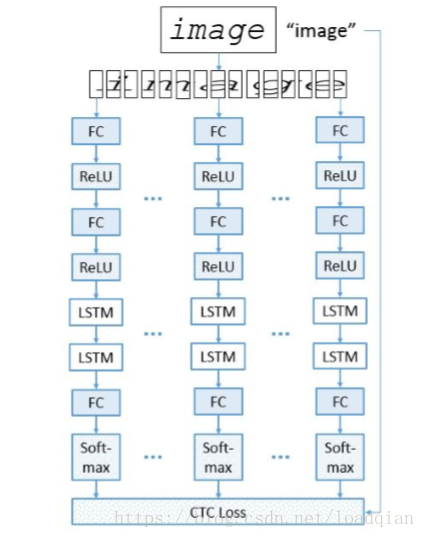
D.训练
该模型的初始学习率为0.001,dropout为0.5。这些超参足以训练模型,而且没有经过精细调整。训练时间超过一个epoch得到的CER为0.04%,WER为0.02%,验证时CER为0.02%和WER为 0.01%。
E.测试
我们使用字符错误率(CER)来衡量错误率,而忽略字错误率(WER)。 对于可比较的CER,较长序列的WER将不可避免地大于较短序列的WER。在一个固定长度的测试数据集上给出单个CER,其中包含Seen,Unseen和Purely Unseen三种类型的N-gram。
实验结果
A.打乱字符实验
在文献21中,我们看到当使用混合语言模型训练设置而不是原始字符语言模型时,LSTM的CER提高了3.6%。然而,其作者并没有调查内部语言模型的可能性。我们首先通过对受控数据集的实验建立隐式LM。这个实验的测试数据集从Wuthering Heights采样并以测试字体呈现的全长英文句子。 我们在这些句子中随机地打乱字符并重新渲染它们,从而形成与原来的句子具有相同字符的数据集,但是具有随机字符语言模型。理想情况下,这两组数据集的实验结果应该是相同的,并且任何差异应该来自隐式LM。表1显示了这些实验的结果。Arial Narrow字体与普通英语句子相比的差异最大,CER提高了2.4%。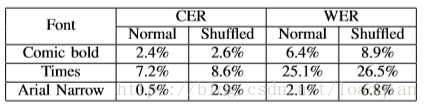
B.N元模型实验
我们已经在打乱字符实验中建立了隐式LM。这个实验的目的是根据字符量化它的上下文限制。与其他语言模型一样,来自隐式LM的上下文优势应该是有限的。具有较长序列的测试集应该从额外字符中获益更多,直到一定长度之后,隐式LM应该在性能上饱和。我们的假设是,性能会随着长度的增加而提高,并且在隐式LM停止考虑更多的上下文帧时达到平衡。我们运行这些从训练集中派生的语言模型,即2元到7元的测试数据集。在表2中观察到超过5个字符时性能停止提高,表明隐式LM可以从双向LSTM模型的上下文中的5个字符中获益。这对应于88种输入字体中,字体大小为16,最宽的测试字体为comic bold。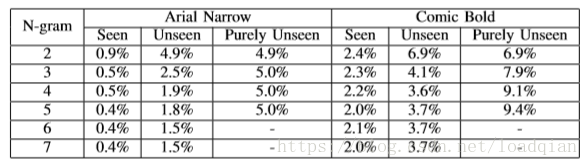
尽管上述分析的理由是合理的,但它本身并不完整。不同长度的测试集中字符频率的波动可能会影响实验。 为了解决这个问题,我们检查了2元到5元数据集中某些字符的结果,如表3所示。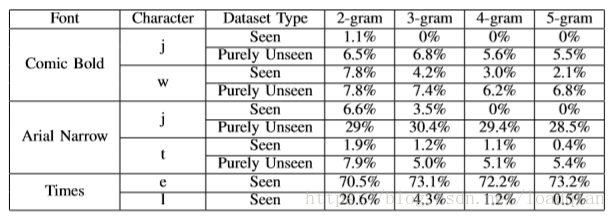
我们通过对Purely Unseen的2元至5元数据集进行CER评估来重申打乱字符实验的结果,忽略缺乏足够样本的6元和7元数据集。在这种情况下,N-gram不仅不遵循训练中可见的语言模型,而且还会竭尽全力确保训练中看到的任何子序列在测试时不会重复出现。根据Seen实验评估中提出的补充推理,我们不期望随着长度的增加性能会有所提高,该错误率应该始终保持在Seen测试集上的错误率之上。表2中的结果与我们的理论是一致的。我们还在表2中展示了Unseen N-gram数据集的实验结果。与先前的推理一致,它的性能一直比Seen数据集差,但增加N-gram的长度可以让结果得到改善,因为这些子序列已经在Seen训练中了。
C.其他字体的情况
到目前为止,我们实验中突出显示的字体显示了Seen序列上所有字符的改进,因此整体性能测量与所有Seen N-gram测试集中的假设一致。但是也并非总是如此,来看第三个测试字体Times Roman的结果。该模型有一个倾向,只能混淆这个字体中的两个字符:l容易和I混淆,e和c在Seen N-gram实验中。随着N增长l的性能提高,错误率从20.6%降至0.5%,但e的性能保持大致相同,为72%左右。单个字符上这个极高的错误迫使任何测试集的结果都由e的频率决定。为了突出这一点,我们运行了另一组Seen实验,在这些实验中,我们重新创建了数据集,其中e的百分比与2元测试集的百分比相同,即6%。我们比较这两组实验结果,调整和不调整e的最终百分比的结果如表4,一旦我们调整了e的百分比,结果就与我们的假设一致。我们检查混淆因子e为什么没有任何改进,但没有发现任何可信的东西,这种错误分布在所有字体大小以及不同的前后字符之间。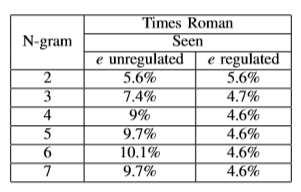
结论
LSTM网络在OCR方面取得了成功,但仍然缺乏对特定任务学习内容的深入了解。我们提供依据表明LSTMs在接受OCR任务训练时,学习一个隐式LM。我们发现,在人工合成的英语数据集上进行测试时,隐式LM使CER最高提高了2.4%。作为现实世界问题的延伸,它也表明,这种隐式LM在多语言OCR任务中可以使CER提高多达3.6%。同时,它使用多达5个字符进行预测,没有必要对当前字符进行预测,正如我们在Times字体中对字符e的出现漠不关心一样。所有实验均使用英语进行,但一般推论适用于任何语言。
原文链接:
https://arxiv.org/pdf/1805.09441.pdf