ResNet——MSRA何凯明团队的Residual Networks,在2015年ImageNet上大放异彩,在ImageNet的classification、detection、localization以及COCO的detection和segmentation上均斩获了第一名的成绩,而且Deep Residual Learning for Image Recognition也获得了CVPR2016的best paper,实在是实至名归。
介绍
本文采用了152层的残差神经网络,比去年的VGG还要多8层,但复杂度确比它低,最后以3.57%的top-5错误率赢得了2015年ILSVRC的冠军,同时在COCO detection 和 COCO segmentation 也获得了第一位。
源于网络深度的重要性,会引发一个问题:网络是否会随着深度的增加而获得越好的效果?增加深度会造成梯度消失或梯度爆炸。解决这个问题的方法是正则化初始化和正则化中间层,这样可以训练十几层网络。但是深层网络刚开始会收敛,之后会退化,也就是说随着梯度的增加,正确率会达到饱和,之后会下降。但这不是过拟合造成的,因为随着网络深度的增加会导致更高的错误率。下图就是一个典型的例子: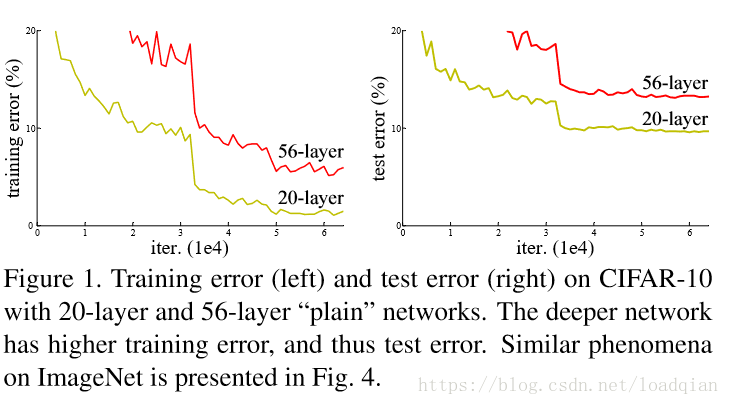
在本文中就使用残差网络来解决随着深度增加导致的性能退化问题,残差块如下: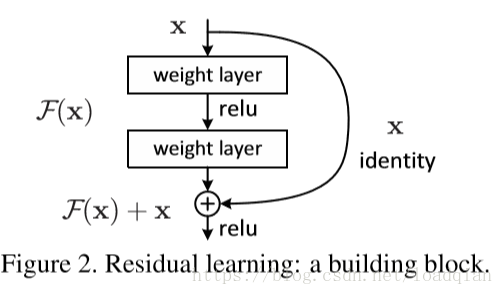
我们假设期望的结果为一个潜在映射H(x),H(x) = F(x)+ x ,则F(x)= H(x) - x 为残差映射,其优化比H(x)更简单,所以使用残差网络相当于学习的目标不是最优解H(x)和全等映射x,而是他们的差。F(x)+ x 可以通过shortcut connections 这种前馈神经网络实现,在我们的实验中,shortcut connections就简化为图中的identity mapping,这样没有引入额外的参数,也不会增加计算的复杂性。
Shortcuts恒等映射
在本文主,我们认为一个残差块应该定义为: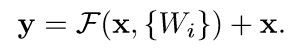
其中,x,y分别代表这一层的输入和输出,F(x,{Wi})代表需要学习的残差映射。例如在上图2中,中间是2层网络,则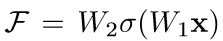
σ表示ReLU,x和F的维度必须相同,如果维度不同,就通过shortcut connections用一个线性投影Ws来使维度相匹配,如下: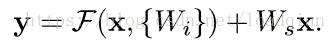
残差函数F比较灵活,本文的实验中F有2-3个层,当然更多也是可以的,当只有1层时,就退化为线性。
网络结构
下图为VGG-19、34层的普通卷积神经网络和34层的ResNet网络的对比图。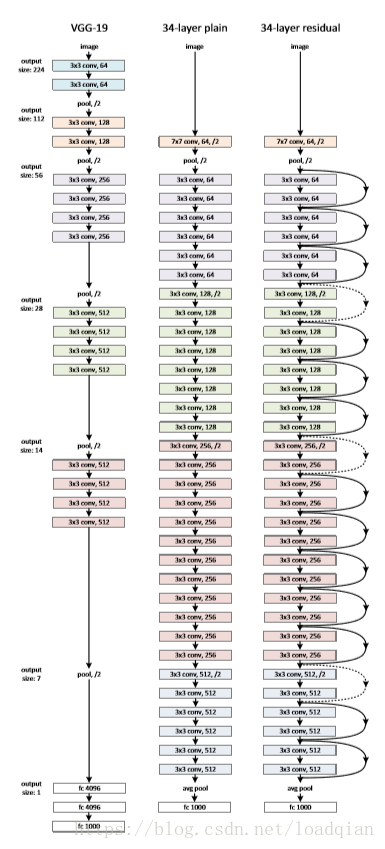
由于shortcuts只能在输入输出维度相同时才能直接使用,当维度增大时,有两种选择:(A)使用额外的zero padding 来增加维度,这种选择不会引入参数(B)使用Ws投影到新的空间,用1*1的卷积实现,直接改变1*1卷积的filters数目,这种选择会增加参数。
实验
(1)使用color augmentation做数据扩增
(2)在每个卷积层之后,激活函数之前使用batch normalization (BN)
(3)SGD作优化,weight decay =0.0001,momentum=0.9
(4)learning rate=0.1,当错误率停滞时除以10
(5)不使用dropout
普通神经网络结构
先评估18层和34层的网络结构,如下: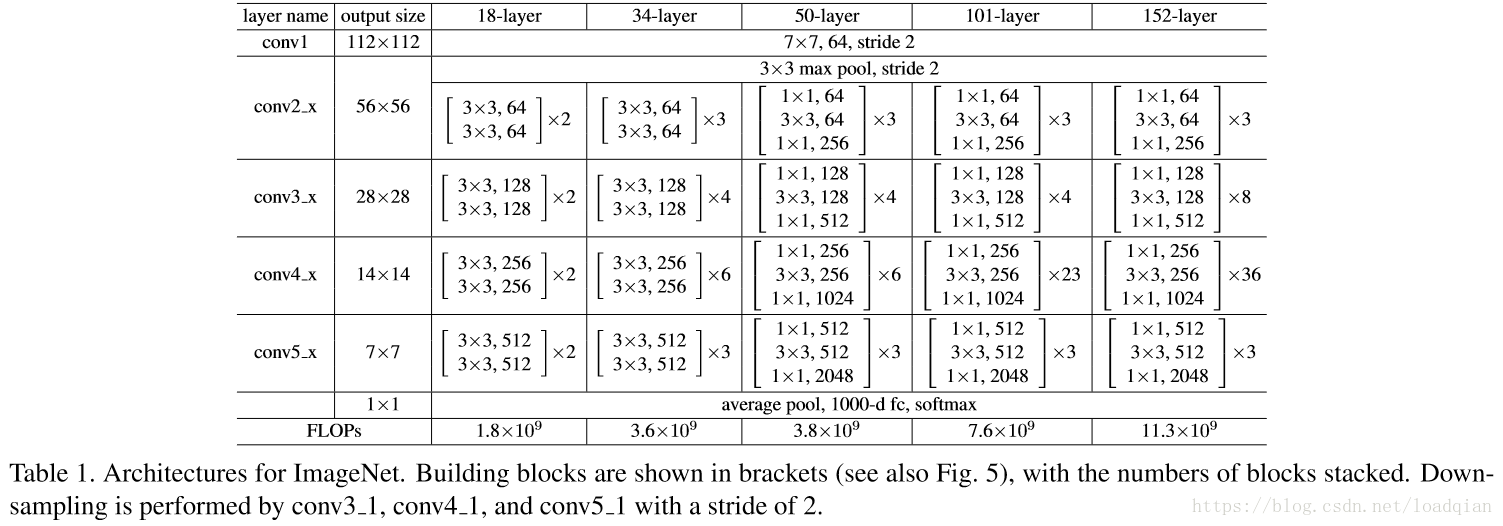
18层和34层的普通神经网络和残差网络实验结果对比如下: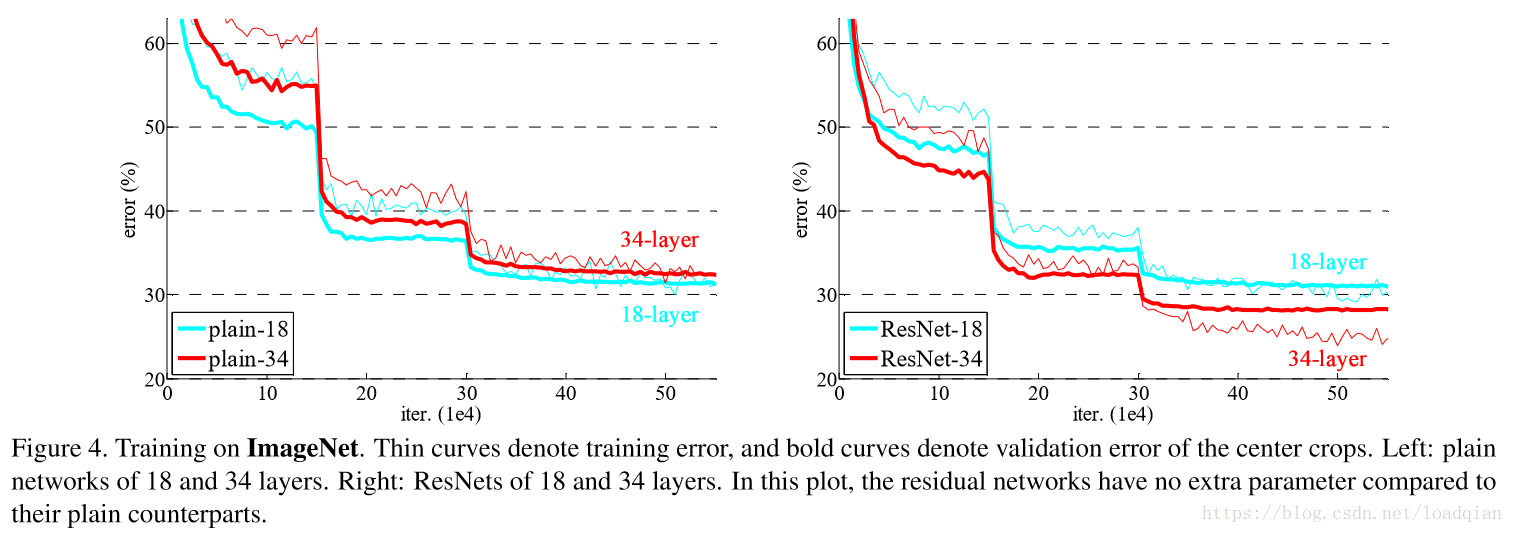
其top-1错误率如下: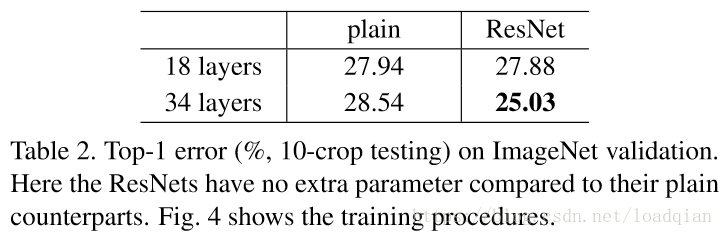
从上面两张图中,可以得出三个结论:
①34层的残差网络比18层的网络错误率降低2.8%,并且34层的网络训练误差更小,在验证集中更generalizable,这说明这种网络结构可以解决退化问题;(实验了plain-18和plain-34,展示了退化问题。说明了退化问题不是因为梯度弥散,因为加入了BN。另外也不能简单地增加迭代次数来使其收敛,增加迭代次数仍然会出现退化问题。)
参考链接:https://www.jianshu.com/p/e58437f39f65
②34层的残差网络比34层的普通网络错误率下降3.5%,证明了残差网络在深度结构中的有效性;
最后,比较18层的普通网络和18层的残差网络,发现18层的残差网络更容易优化,收敛速度更快。
对于同等映射维度不匹配时,匹配维度有两种方法,zero padding不会增加参数,projection投影法会引入参数。本文比较了三种方式:(A)渐增维度使用zero-padding shortcuts(B)渐增维度使用projection shortcuts,其他使用全等映射(C)维度匹配或不匹配的同等映射全用投影法。实验结果如下: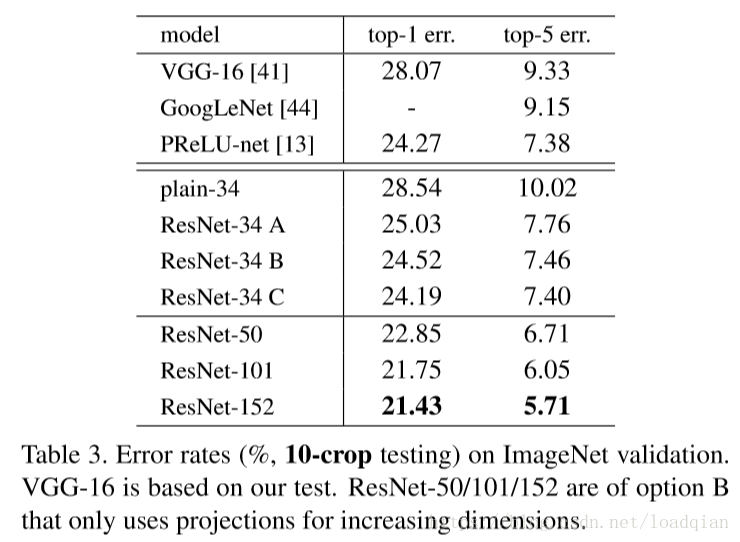
从上可以发现,B比A的效果稍好一些,因为zero padding的部分没有参与残差学习。C比B也稍好一些,但是考虑到不增加复杂度和参数free,不采用这种方法。
更深的瓶颈结构: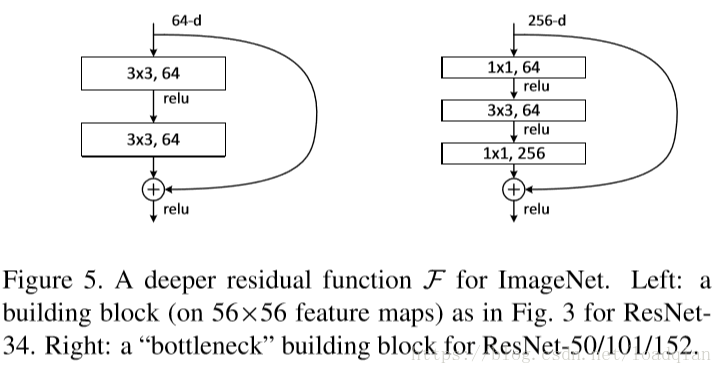
考虑到我们能承受的训练时间,将残差块(building block )修改为瓶颈(bottleneck)设计如上图。首端和末端使用11卷积用来削减和恢复维度,剩下中间3\3的卷积为瓶颈部分。与原来结构相比,这两种结构的时间复杂度相似。此时,没有引入参数的全等映射对这种瓶颈结构就显得非常重要,如果使用投影法(projection)会使得时间复杂度和模型大小加倍,所以要使用zero padding的同等映射。
探索大于1000层的网络
我们设置大于1000的网络结构深度,我们的方法没有出现优化困难的问题,测试误差仍然比较好,为7.93%,但是结果比110层的网络要差,尽管两者的训练误差相似,这是因为过拟合,可以使用maxout/dropout来解决过拟合的问题,但本文的实验没有使用任何maxout/dropout等强大的正则化方式。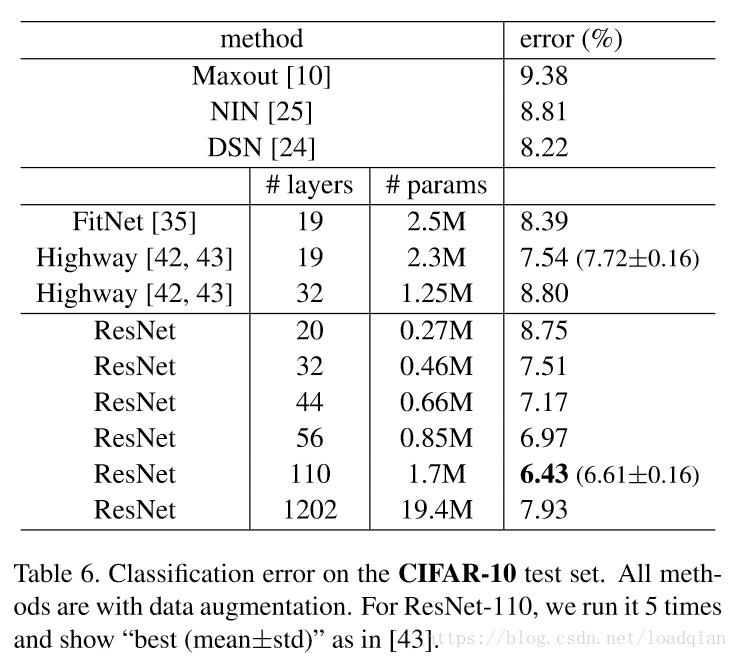
程序实现
这里我以CIFAR10为数据集,写了一个简单的ResNet用于图像分类,最后的top-1正确率为83%左右,主要程序如下: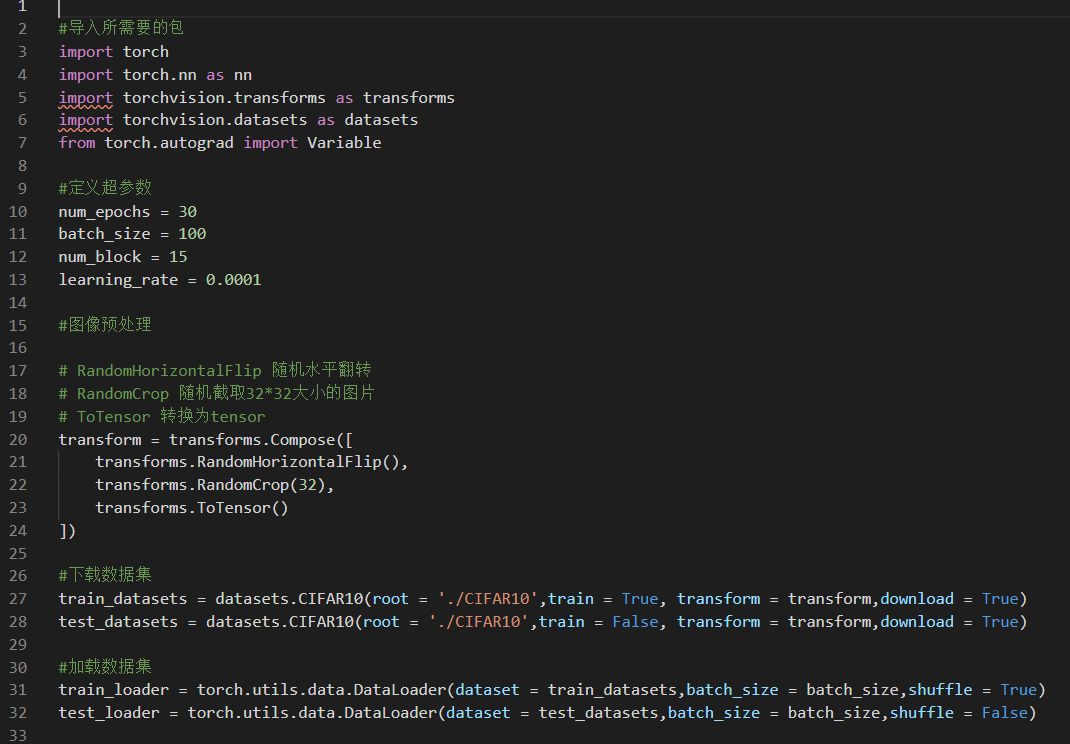
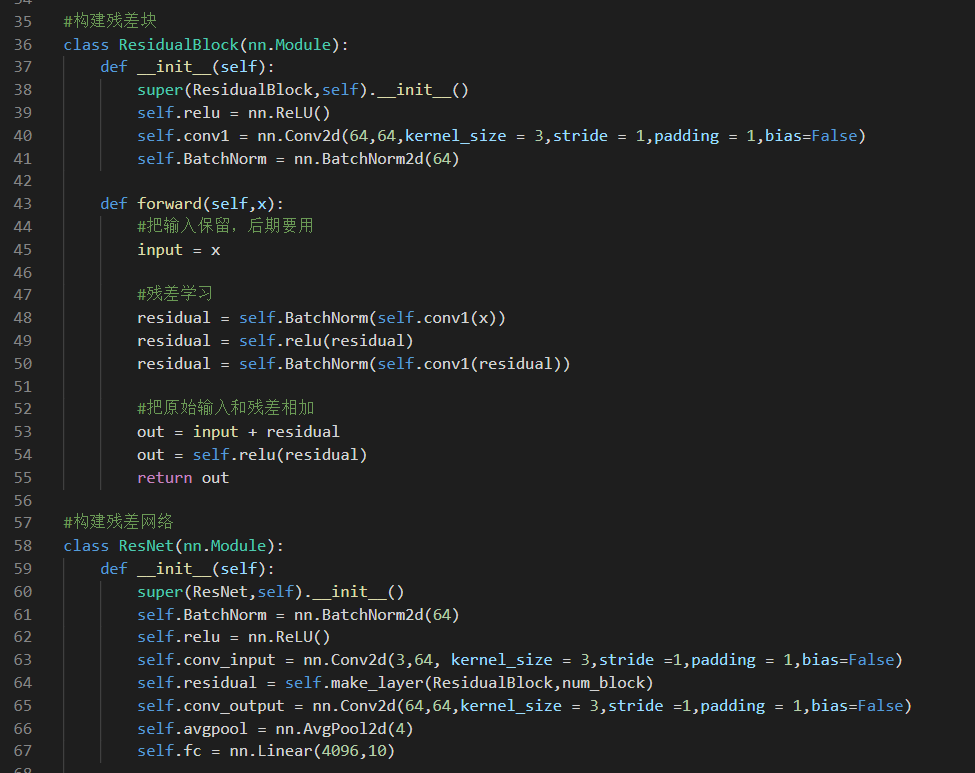
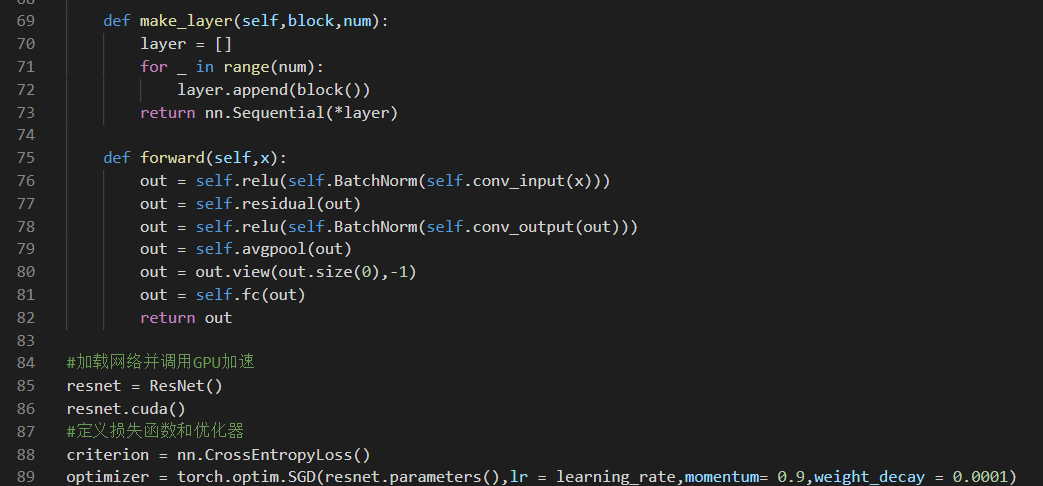
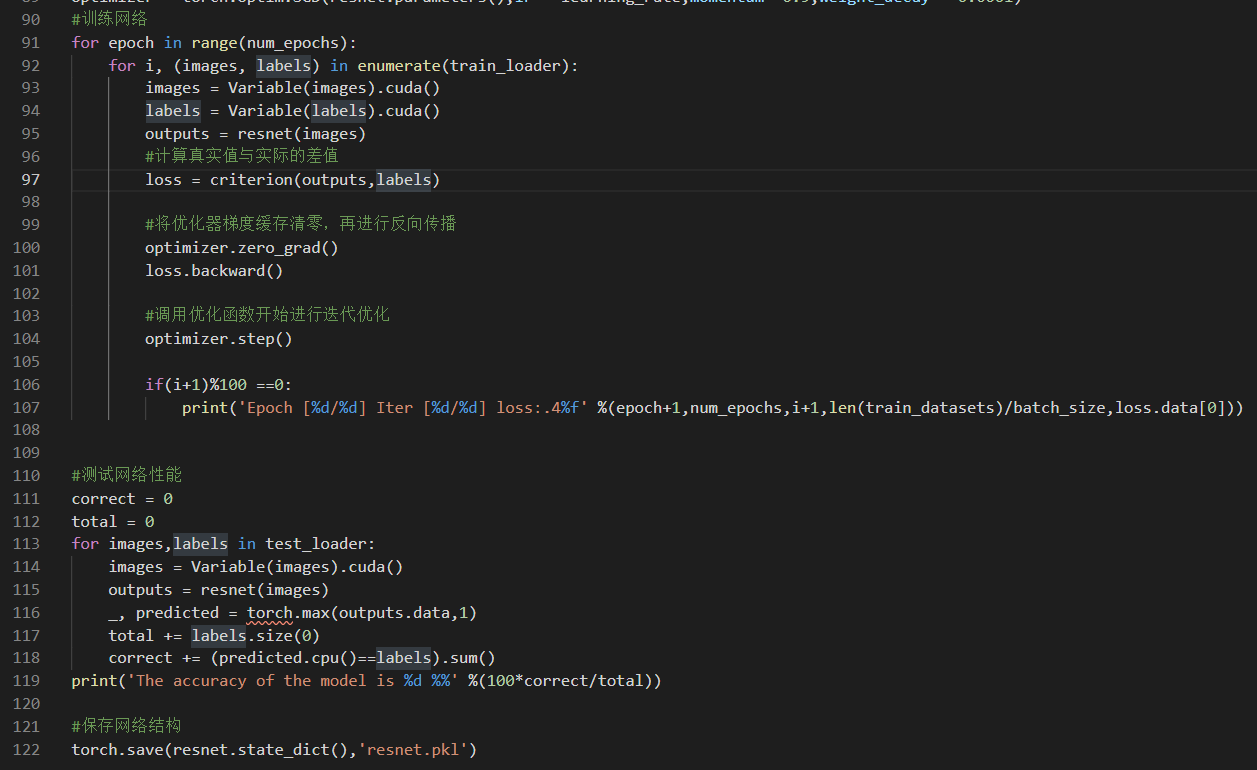
参考链接:
https://www.jianshu.com/p/e58437f39f65
https://blog.csdn.net/diamonjoy_zone/article/details/70904212
推荐两篇写得比较详细的残差网络的博客:
https://blog.csdn.net/loveliuzz/article/details/79117397
https://blog.csdn.net/qq_40027052/article/details/78261737