Rich feature hierarchies for accurate object detection and semantic segmentation
Author : Ross Girshick Jeff Donahue Trevor Darrell Jitendra Malik
1.介绍
不同于以往的特征检测算法HOG和SIFT,本文提出了一种新的算法将特征提取与CNNs结合起来,即R-CNN:Regions with CNN features,如图1:
R-CNN检测流程如下:
(1)首先输入一张自然图像;
(2)使用Selective Search提取大约2000个候选区域(proposal);
(3)对每个候选区域的图像进行拉伸形变,使之成为固定大小的正方形图像,并将该图像输入到CNN中提取特征;
(4)使用线性的SVM对提取的特征进行分类
遇到的问题:带标签的数据比较少,不足以训练一个庞大的CNN网络,传统的解决方法是采用无监督的预训练(pre-training)和监督的fine-tuning;本文的贡献是在一个大的辅助数据集(ILSVRC)上使用监督的pre-training,接着是在一个小的数据集(PASCAL)上使用 domain-specific的 fine-tuning。在实验中,使用 fine-tuning做检测的mAP结果提高了8个百分点。
2. 使用R-CNN的目标检测
我们的目标检测系统包含三个模块,第一,产生不依赖于特定类别的特征区域,作为一组候选目标;第二,一个庞大的卷积神经网络用来对每个区域选取固定长度的特征向量;第三,一系列特定类别的线性SVM分类器。
2.1模型设计
候选区域: R-CNN对特定的候选区域方法来说是不可知的,所以选择selective search方式对每张图提取了约2000个大小不一候选区域。
特征提取:使用Caffe框架提供的CNN模型从每个候选区域中提取4096维的特征向量,这些特征是由mean-subtracted 227227的RGB图像通过5个卷积层和2个全连接层正向传播计算得到的。
CNN结构要求输入尺寸固定为227227,所以要对候选区域进行缩放,为避免缩放操作对识别检测精度的影响,作者对缩放过程做了优化,比如对候选区域边界扩展、warp等,并选取最好的缩放方式。我们选择最简单的转换方式,warp边界框周围的所有像素使其达到要求,warp大小为p个像素(这里p=16),下图展示了随机采样的变形后的训练区域。
2.2 测试时间检测
在测试阶段,使用selective search选择近2000个候选区域,将每个region proposals归一化到227x227,然后通过CNN前向传播将最后一层得到的特征提取出来。对于每一类,用训练好的SVM对提取的特征向量进行打分,运用贪心的非极大值抑制去除相交的多余的框。非极大值抑制(NMS)先计算出每一个bounding box的面积,然后根据score进行排序,把score最大的bounding box作为选定的框,计算其余bounding box与当前最大score与box的IoU,去除IoU大于设定的阈值的bounding box。然后重复上面的过程,直至候选bounding box为空,然后再将score小于一定阈值的选定框删除得到一类的结果。作者提到花费在region propasals和提取特征的时间是13s/张-GPU和53s/张-CPU,可以看出时间还是很长的,不能够达到及时性。
运行时间分析:两个性质使得检测更高效:1.在分类中所有的CNN参数共享;2.与其他常用方法相比,用CNN计算的特征向量是低维的。共享参数的结果就是所有类别上的时间花销都是平摊的。特定类别的计算是特征与SVM权值及非极大值抑制的点乘,在实验中,所有点乘可以批处理成矩阵乘法,特征矩阵为2000*4096,SVM权值矩阵为4096*N,其中N为类别数量。
将实验结果与使用DMPs和哈希的可伸缩检测对比,其再在VOC2017数据集上得到的mAP约16%,引入10k种错误选择类每处理一张图像需要5分钟;而我们的方法,10k的检测器在CPU上跑只需约1分钟,由于没有近似值mAP达到59%。
2.3训练
有监督预训练:
在一个庞大的数据集(ILSVRC2012)上预训练CNN,使用开源的Caffe CNN库,得到的top-1错误率比ILSVRC2012分类高2.2%,这是因为我们简化了训练过程。
Domain-specific 微调(fine-tuning):
为了使CNN适应检测任务和wrap候选窗口任务,继续使用SGD训练参数。首先基于ILVCR-2012中ImageNet所有数据训练一个1000分类的模型,作者尝试了VGG-16和AlexNet,单从精度方面VGG-16优于AlexNet,但由于VGG-16速度方面大幅落后于AlexNet,因此作者最终选用了AlexNet,我们简称为模型1。
其次,在上述模型1的基础上,基于在图像上提出的候选区域,筛选出符合条件的,对网络进行微调。在微调的过程中,将上述模型1的最后一层输出类别个数改为要检测的目标类别个数加1,以VOC为例,最后微调的模型输出类别为20+1=21类,即物体类别数加上背景。为了保证训练只是对网络的微调而不是大幅度的变化,网络的学习率只设置成了0.001。
在微调模型的过程中,最关键的点在于候选区域的筛选和标签的获得,这里需要引入一个概念:IoU(intersection-over-union),IoU描述了两个框之间的重叠度,计算方法为两个框的交集除以两个框的并集。
根据候选框和真实标定框(Ground Truth)之间的IoU值确定该候选框的标签,选取候选框与真实标定框IoU最大的标定框,若IoU大于0.5,标签即取为该真实框内物体的类别标签。如果候选框与任何一个真实标定框之间IoU均小于0.5,该候选框的标签即为背景。基于筛选出的包含各个类别和背景的候选区域对网络进行微调,即可得到最终用于提特征的深度网络。然后在训练的每一次迭代中都使用32个正样本(包括所有类别)和96个背景样本组成的128张图片的batch进行训练(这么做的主要原因是正样本图片太少了)。
特定类别的分类器:
最终对候选框类别的分类,对于每个类别,均训练了一个二分类的SVM,比如对于狗,训练一个SVM来判断一个候选区域是或者不是狗。还是以VOC为例,则训练了20个SVM分类器。
在SVM的训练过程中,对候选区域的选择较为严格,正例为真实标定框,负例为与真实标定框IoU值小于0.3的候选框,将这些框过一遍上一步中微调好的模型,提取最后一层FC-4096维的特征向量,喂给这些框对应类别SVM进行训练。由于负例很多,作者采用了标准的hard negative mining方式。
利用回归的方式对框位置进行精修:
在经过上述所有步骤得到最终框之后,为了使得框的位置更加精确,作者对框进行了线性回归。选取判定为该类别的框与标定框的IoU大于0.6的候选框,提取深度特征进行回归。
整个test过程如下,在整幅图中利用Selective Search选取约2000个候选框,提取2000个框的深度特征,分别喂给各个类别的SVM分类器,判断是否包含该物体。由于一个物体可能有多个候选框,所以对同一类别的多个框做NMS(非极大值抑制),选取最优的框,将剩下的框分别进行框回归,得到最终结果。
2.4 PASCAL VOC 2010-12的结果
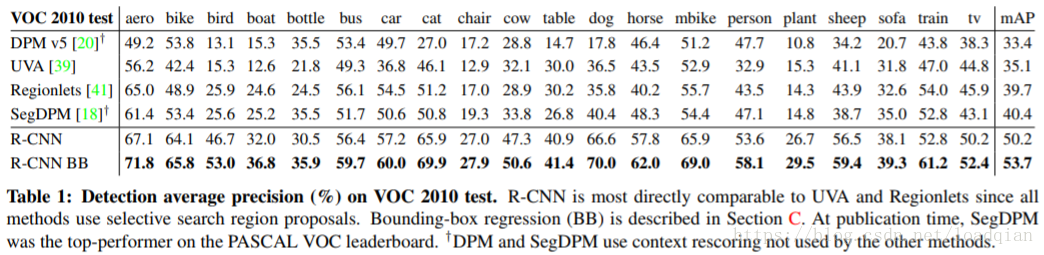
2.5 ILSVRC2013 目标检测结果
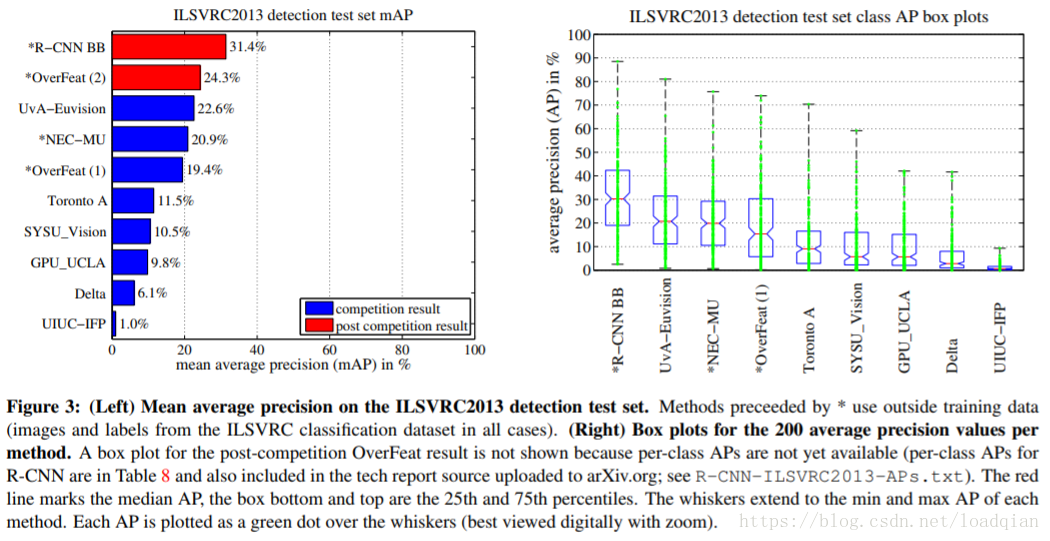
参考链接:
http://www.xue63.com/toutiaojy/20171229G0ISRV00.html