感觉很久没有更新博客了,之前一直在做项目,现在项目中期差不多完成了,可以暂时先告一段落了。正式的研究生生活也已经过去一个多月了,虽然之前一直有磕磕碰碰,现在总算步入正轨啦,希望之后可以更好吧!不bb了,讲正事(一本正经脸)
摘要
图像增强技术常用于图像预处理来提升图像的整体感官质量,使之在后续的卷积神经中表现出更好的效果。然而现有的图像增强算法大多是为了满足观察者的感官质量,在本文中我们学习能仿真图像增强和复原的CNN结构来了提高图像的分类效果而不仅仅是人类的感官质量。最后,我们提出了一个包含一系列增强滤波器的标准CNN结构,通过端到端的动态滤波器学习来增强图像的特定细节。使用四个基准数据集CUB-200-2011, PASCAL-VOC2007, MIT-Indoor, 和DTD进行测试,取得了不错的效果。
介绍
图像增强常用于分类、目标检测等任务的预处理,增强主要是为了去除模糊、噪声、低对比度、压缩等来提高图像的细节,常用的方法有高斯平滑(Gaussian smoothing),各向异性扩散(anisotropic diffusion),加权最小二乘(weighted least squares (WLS) )和双边滤波(bilateral filtering)等,这些方法往往需要复杂的优化且运行时间长。
本文的主要贡献是联合优化一个CNN用于增强和分类,我们通过动态卷积自适应地增强图像主要部分的特征来实现这一点,这使得增强CNN能够选择性地只增强那些有助于提高图像分类的特征。网络结构如下: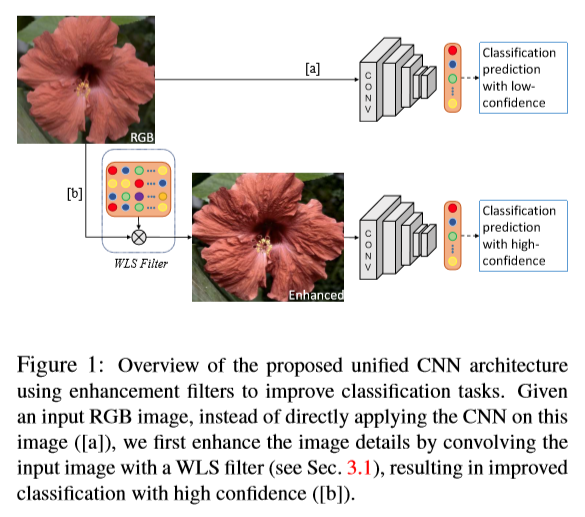
本文中提出的方法
动态增强滤波器
本部分的模型根据端到端学习方法中的输入图像和输出增强图像对来学习不同的增强方法中有代表性的增强滤波器,目标是提高分类效果。对于一张输入的RGB图像I,先把它转化成亮度-色度(luminance-chrominance)Y CbCr 彩色空间,增强算法用于RGB图像的亮度通道,可以使得过滤器修改整体色调属性和图像锐度,而不影响颜色。 亮度图像\(Y \in {R^{ {\rm{h*}}w}}\)卷积一个增强算法\(E:Y \to T\),产生增强后的目标输出图像\(T \in {R^{ {\rm{h*}}w}}\),h和w分别代表图像Y的高和宽。具体结构如下: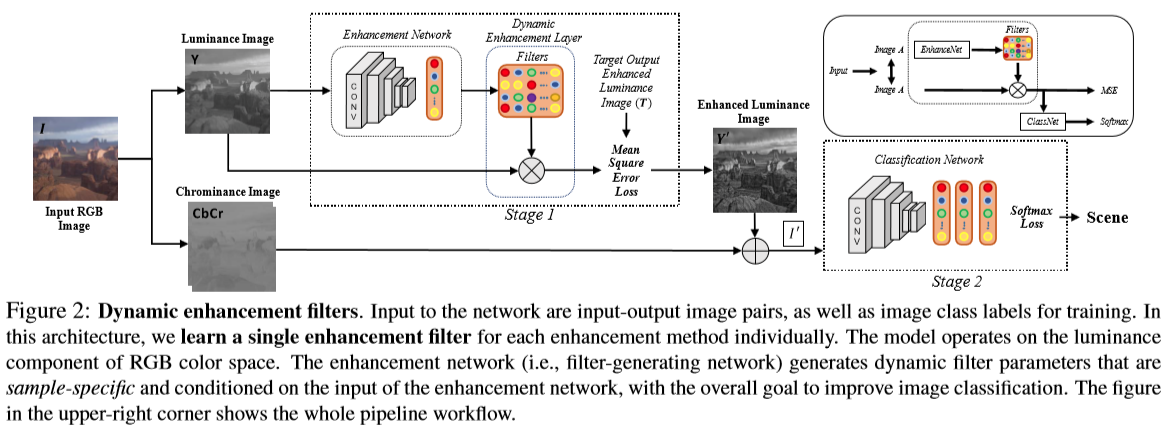
一、增强阶段
增强网络(EnhanceNet)由卷积层和全连接层组成,输入是单通道的亮度图像Y,输出是滤波器\({f_\Theta }\),\(\Theta \in {R^{s*s*n}}\),\(\Theta \)是增强网络动态产生的转换参数,s是滤波器大小,n是滤波器数量,对于一幅单通道的亮度图像产生的单一滤波器数量等于1。这个生成的滤波器对于输入图像中每个位置\((i,j)\)产生其输出图像\(Y’(i,j) = {f_\Theta }(Y(i,j)),Y’ \in {R^{h*w}}\),滤波器对于每一张输入图像Y都是特定的,对于不同的样本参数也不一样。参数\(\Theta \)通过训练目标图像T和输出图像Y’之间的均方误差(MSE)得到。之后,加上色度部分CbCr得到变换后的RGB图像I’。我们发现滤波器可以学到期望的变换并正确的增强图像,图5可以看到动态增强后的图像纹理。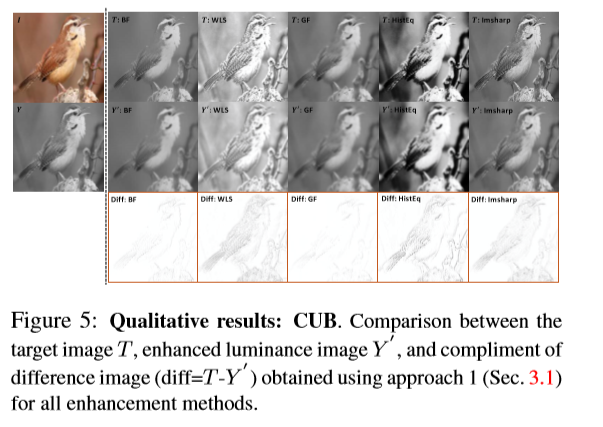
二、分类阶段
从增强阶段得到的输出图像I’作为分类网络(ClassNet)的输入,分类网络最后的卷积层和分类层之间有全连接层,全连接层和C分类层的参数使用预训练的网络进行微调(fine-tuning) 。
端到端的学习
阶段1-2包含了两个损失函数——MSE(enhancement)和softmax-loss \(L\) (classification),通过使用SGD优化器在ClassNet和EnhancedNet中端到端梯度传播,实现联合优化,总的损失函数如下:
\[\begin{array}{l}Los{s_{Filters}} = MSE(T,Y’) + L(P,Y)\\{P_q} = \frac{ {\exp ({a_q})}}{ {\sum\nolimits_{r = 1}^C {\exp ({a_r})} }},L(P,Y) = - \sum\limits_{q = 1}^C { {y_q}log({P_q})} \end{array}\]
其中,a 为ClassNet最后一个全连接层的输出,连接到C分类网络softmax函数,y是图像I的真是标签,C为类别数。整个过程进行fine-tune直至收敛,因此增强滤波器可以在动态增强层中学习。同时,联合优化使得损失梯度可以从ClassNet中反向传播至EnhanceNet,来优化滤波器的参数。
静态分类滤波器
所有的动态滤波器求均值可以得到静态滤波器,将其卷积上原始输入图像I中的亮度部分Y再加上色度部分就可以转化为RGB图像I’,整体结构如图3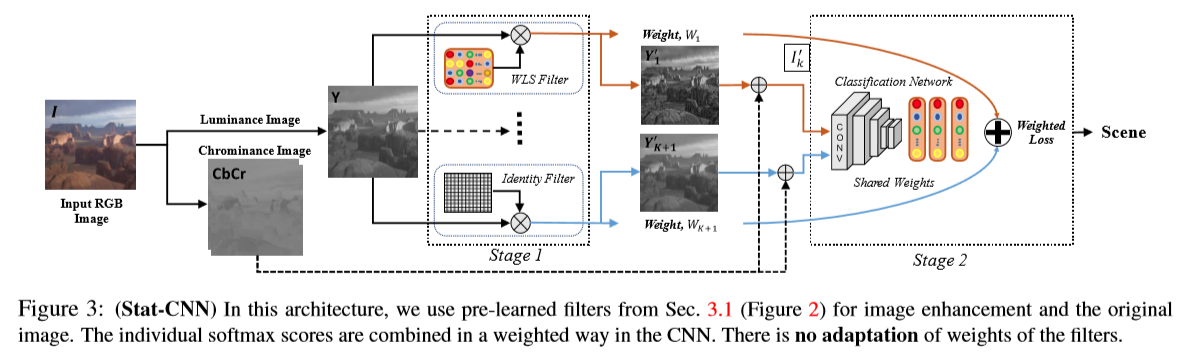
一、增强阶段
首先提取K种图像增强算法中预训练好的滤波器,对于给定的输入亮度图像Y,这些滤波器\({f_{\Theta ,k}}\)卷积上输入图像可得\({Y_k}’ = {f_{\Theta ,k}}(Y),k \in K\),由于有些基于学习的增强得到的结果不如原始图像,因此我们引入一个恒等滤波器(K+1)来产生原始图像,并比较了两种不同的权重(1)设置相同的权值\(1/K\);(2)根据MSE给出权重。这部分的输出为一系列增强后的亮度图像及对应的权重,再与色度通道结合转换回RBG图像\({I_{\rm{k}}}’\)
二、分类阶段
K种图像增强方法增强后的图像\({I_{\rm{k}}}’\)和原始图像一一作为分类网络的输入,包括其类别标签和表示增强方法重要性的权重\({W_k}\)。同上一个网络类似,全连接层和C分类层的参数在端到端的学习中使用预训练的网络进行微调(fine-tuning) 。
端到端的训练
训练网络的损失为\({W_k}\)与softmax损失\({L_k}\)的加权和,如下:
\[Los{s_{S{\rm{tat}}}}{\rm{ = }}\sum\limits_{k = 1}^{K + 1} { {W_k}{L_k}(P,y)} \]
其中,权重W为K中增强方法的重要程度,\({W_{K + 1}} = 1\)为原始图像的权值。
多动态滤波器分类
整体的网络结构如图4: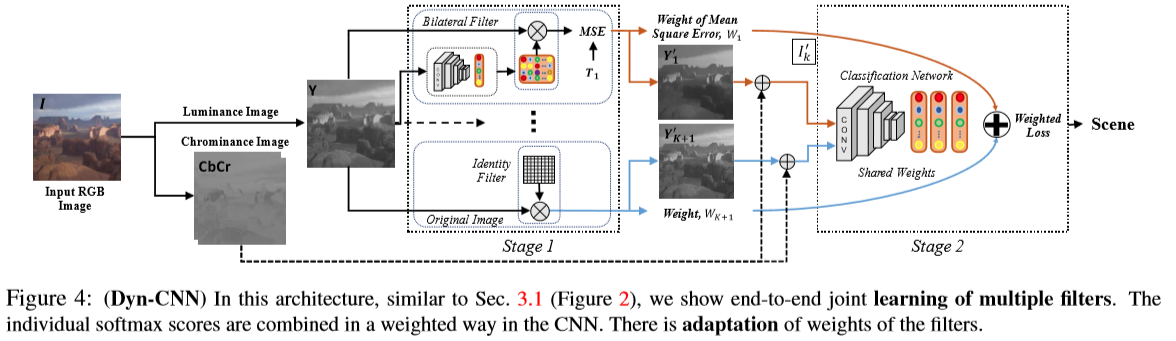
在上述结构中,为计算各增强方法的权值,将增强后图像的MSE转换为权值\({W_k}\),最后计算权重\({W_k} = {W_k}/\sum\limits_{m = 1}^K { {W_m}} \),K种方法的权值和为1。增强后的图像误差最小则权值最大,反之亦然。同时,我们也比较了相同权值的情况,然后发现基于MSE的权值能得到更好的结果。与方法2类似,这边也将原始图像卷积上一个恒等滤波器(K+1),权值为1。在训练过程中,训练集和验证集使用交叉验证来评估权值,在测试阶段使用这些计算好的权值。此外,在没有权重正则化的情况下训练网络,使得模型在整个学习过程中无法收敛,并导致过度拟合,导致性能显著下降。
端到端的训练
扩展上述方法的损失函数,加上MSE项联合优化基于分类目标的K增强网络,这个损失针对特定的样本,如下:
\[Los{s_{Dyn}} = \sum\limits_{k = 1}^K {MS{E_k}({T_k},{Y_k}’) + \sum\limits_{k = 1}^{K + 1} { {W_k}{L_k}(P,y)} } \]
实验
本文的目的使用增强滤波器来提高一般CNN结构的基准(baseline)结果。
数据集
选取了四个数据集,分别为用于fine-grained分类的CUB-200-2011 CUB、目标分类PASCAL-VOC2007 (PascalVOC)、场景识别MIT-IndoorScene (MIT) 和纹理分类Describable Textures Dataset (DTD),对于每个数据集,分为训练集/验证集/测试集来评测分类的正确率,数据集细节如下: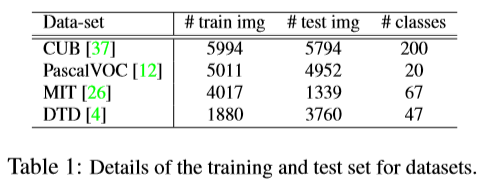
目标输出数据
使用5种增强方法E(K=5):(1)weighted least squares (WLS) filter,(2) bilateral filter (BF), (3) image sharpening filter (Imsharp), (4) guided filter (GF), (5) histogram equalization (HistEq)。在训练阶段,给定一张输入图像,先转化成亮度和色度空间,然后对亮度图进行增强,并用于训练。WLS和Imsharp均使用其默认参数,BF,GF,HistEq的参数根据每张图进行调整,因此不需要设置参数。在ConvNet测试阶段,输入的要么是RGB图像,要么是使用静态或动态过滤器的增强RGB图像
Fine-Grained分类
滤波器大小
经过实验发现,6*6的滤波器大小可以得到预期的转换并对输入图像正确增强,得到更锐化的边缘细节。
权值设置
经过实验发现,基于MSE的权重设置比相同权值能取得更好的结果,最终的权重如下:
对比结果如下: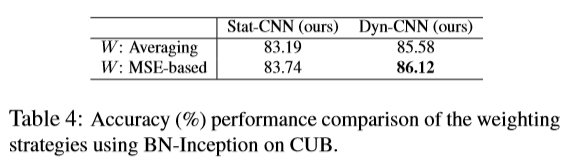
卷积结构
比较了AlexNet, GoogLeNet和BN-Inception,发现BN-Inception的效果最好,如下: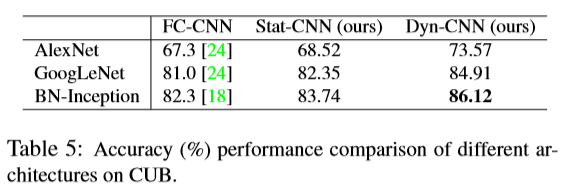
结果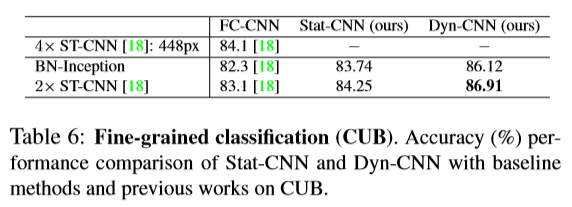
目标分类&室内场景识别&纹理分类
对于这三个数据集,分别使用VGG-16和AlexNet进行测试,结果如下: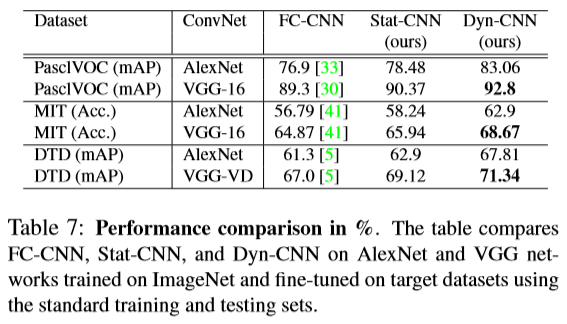
总结
本文最大的创新之处在于一般的图像增强方法没有评判标准,所以本文将图像增强与分类任务结合起来,以提高图像分类正确率作为图像增强的标准,更具有实际意义。